I'm going to go hide in my little cave and tinker away with my programming for a while.
When I emerge, maybe there will be a new tower defense game available on Xbox Live.
If I don't give up before then.
Monday, December 29, 2008
Monday, December 15, 2008
VCE Results
ENTER: 97.70
Raw subject scores:
Scaled Study Scores:
I did well enough. My first preference, Bachelor of Science at The University of Melbourne, requires an ENTER score of only 85.00. Party time?
Raw subject scores:
CH03 - Chemistry
GA 1: B+
GA 2: A+
GA 3: A+
Study Score: 38
EN01 - English
GA 1: A
GA 2: A
GA 3: B+
Study Score: 34
MA08 - Mathematical Methods
GA 1: A+
GA 2: A+
GA 3: A+
Study Score: 45
MA09 - Specialist Mathematics
GA 1: A+
GA 2: A
GA 3: A+
Study Score: 40
PH03 - Physics
GA 1: A+
GA 2: A+
GA 3: A+
Study Score: 46
Scaled Study Scores:
English: 32.48
Specialist Mathematics: 47.91
Mathematical Methods: 47.89
Physics: 47.75
Chemistry: 42.67
Info Tech: Software Development (2007): 39.71
Aggregate: 184.2
I did well enough. My first preference, Bachelor of Science at The University of Melbourne, requires an ENTER score of only 85.00. Party time?
Friday, December 12, 2008
LOLExec: A Dynamic LOLCODE Interpreter
Well, today I released version 1.0 of LOLExec. LOLExec is an interpreter for the esoteric programming language LOLCODE. For example, here's the Hello World program:
I've put it up for download here:
http://www.microngamestudios.com/lolexec.html
In the binary executable package, I've included a few sample applications along with the interpreter: for example a prime number finder and a few solutions to Project Euler problems implemented in LOLCODE. Also available is a large suite of unit tests that I wrote during the course of development. Feel free to use them as you wish.
HAI
CAN HAS STDIO?
VISIBLE "HAI WORLD!"
KTHXBYE
I've put it up for download here:
http://www.microngamestudios.com/lolexec.html
In the binary executable package, I've included a few sample applications along with the interpreter: for example a prime number finder and a few solutions to Project Euler problems implemented in LOLCODE. Also available is a large suite of unit tests that I wrote during the course of development. Feel free to use them as you wish.
Friday, December 5, 2008
Finishing school
So on wednesday evening, Melbourne High School had its annual Speech Night event at Hisense Arena (formerly Vodafone Arena) in central Melbourne. It was effectively a graduation ceremony for us year 12's, and marked the end of our time at MHS.
My 4 year journey through MHS has certainly been memorable, and I am certain that I'll not forget it. I sure enjoyed my time there and, as cliche as it sounds, I'm sad that my time there has now come to an end.
That said, I am proud to be able to call myself an Old Boy of Melbourne High School. Now all that's left is to eagerly await the announcement of the VCE results on December 15th.
I sleep now. Valedictory dinner last night, "slept" over at a friend's house afterwards, played Halo 3 and talked all night instead of sleeping. ^_^
My 4 year journey through MHS has certainly been memorable, and I am certain that I'll not forget it. I sure enjoyed my time there and, as cliche as it sounds, I'm sad that my time there has now come to an end.
That said, I am proud to be able to call myself an Old Boy of Melbourne High School. Now all that's left is to eagerly await the announcement of the VCE results on December 15th.
I sleep now. Valedictory dinner last night, "slept" over at a friend's house afterwards, played Halo 3 and talked all night instead of sleeping. ^_^
Friday, November 14, 2008
eGames Expo
So I was at the eGames Expo today at the Melbourne Exhibition Centre. I played games, shook hands with Yahtzee, and recieved an 8GB 4th-Gen iPod Nano from Monash University.
Was a fun day.
Was a fun day.
Wednesday, October 22, 2008
Rickrolling the school
So today I rickrolled the entire school as a final prank. A little bit of internet-inspired idiocy to break up an otherwise bland day. :)
http://www.youtube.com/watch?v=PbACIVJXsTA
http://www.youtube.com/watch?v=PbACIVJXsTA
Monday, October 20, 2008
XKCD Everywhere
So today is final week for Year 12's at MHS. I have no idea when muck-up day actually is, so I've just referred to this entire week as "muck-up week".
Since I'm in Year 12 and this is our last year, a few friends and I thought we might leave a little bit of a parting gift for our comrades at school. Fans of XKCD that we were, what better way to spend our mischief than to spread the word of XKCD?
So we did. Over a weekend, I printed out 400 different XKCD comics. 5 times. 2000 odd sheets of paper bundled up and brought to school today in the wee hours of the morning.
Even though we started at about 6:30AM, we still had at least 500 comics left to tape up by the time the form assembly bell went at about 8:50AM. But by that time, a good portion of the 20's castle building was already plastered in XKCD. We put up the rest of them later in the day.
Total cost: about $100. $20 for paper, $45 for toner, the rest for a heck of a lot of expensive tape. We couldn't use regular tape on the walls because it would peel the paint off - so I had to buy magic tape for $5 a roll (stupid 3M has a monopoly on the adhesives market). It was a waste of money, some would say. I beg to differ. Bringing the word of XKCD to the masses is a very worthwhile use of money. Besides, I recently came into $3000 in cash... gotta use it for something!
I wonder how long these comics will stay up there (and who's going to clean this mess up?)
Preparation - the stacks of XKCD:

The front of the unsuspecting school at 6:20 AM:

Maths department:




Science department:


Dining hall:



Hallways/stairwells:




On a completely unrelated note, I happened to have my camera handy while the teacher dunking was happening:

Since I'm in Year 12 and this is our last year, a few friends and I thought we might leave a little bit of a parting gift for our comrades at school. Fans of XKCD that we were, what better way to spend our mischief than to spread the word of XKCD?
So we did. Over a weekend, I printed out 400 different XKCD comics. 5 times. 2000 odd sheets of paper bundled up and brought to school today in the wee hours of the morning.
Even though we started at about 6:30AM, we still had at least 500 comics left to tape up by the time the form assembly bell went at about 8:50AM. But by that time, a good portion of the 20's castle building was already plastered in XKCD. We put up the rest of them later in the day.
Total cost: about $100. $20 for paper, $45 for toner, the rest for a heck of a lot of expensive tape. We couldn't use regular tape on the walls because it would peel the paint off - so I had to buy magic tape for $5 a roll (stupid 3M has a monopoly on the adhesives market). It was a waste of money, some would say. I beg to differ. Bringing the word of XKCD to the masses is a very worthwhile use of money. Besides, I recently came into $3000 in cash... gotta use it for something!
I wonder how long these comics will stay up there (and who's going to clean this mess up?)
Preparation - the stacks of XKCD:

The front of the unsuspecting school at 6:20 AM:

Maths department:




Science department:


Dining hall:



Hallways/stairwells:




On a completely unrelated note, I happened to have my camera handy while the teacher dunking was happening:

Wednesday, September 17, 2008
Art of Defence Download
Just like with NextWar, I've put up Art of Defence for free download. You can get it here:
http://www.microngamestudios.com/aod.html
http://www.microngamestudios.com/aod.html
Tuesday, September 16, 2008
Monash IT Challenge 2008 Result
I guess I'm on a roll. :D
About a month ago, I submitted a tower defence game called "Art of Defence" to Monash University to compete in their IT Challenge 2008 Competition. Today, at the BMW Edge Cinema at Federation Square, Monash held a prize ceremony for this competition. Art of Defence won first place in the Games Development category.
To be honest, I was surprised to win this competition - I had no idea the game would do so well. I wrote the core code for the game back in 2006, when I was in Year 10 (and just having completed Game Design as an elective at school). Art of Defence was written in C++, using DirectX 9.0. Sometime later on, I'll host it on microngamestudios.com for free download, just like I did for NextWar.
I'm not actually sure what the first prize is, but rumour has it that it's a new iPod Nano*. According to Monash, they're having some supply issues so it'll be a few weeks until I get the prize.
Once again, thanks to Mr. Adrian Janson for sponsoring me in the competition, and to the faculty of IT at Monash and to Andrew Owen for their work in setting up the competition. And congratulations to Alan Lahiff, too, who was the other Melbourne High prize winner. He won prizes in the Programming and Database categories, and came second in the running for the IT Challenge Student of the Year. He won a heck of a lot of stuff, so hats off to him!
Anyway, here's a photo of the trophy:

The text reads:
IT Challenge 2008
Category
Game Development
1st Place
Adrian Tsai
Melbourne High
* EDIT: I've just recieved an email from Andrew Owen about the prize - first prize in my category recieves a brand new 4GB iPod Nano! According to Wikipedia, I guess that would make it a 4th Gen iPod Nano. I'll also be getting free tickets to IDEF, the International Digital Entertainment Festival, which will be on during the 14th-16th November. Can't wait!
About a month ago, I submitted a tower defence game called "Art of Defence" to Monash University to compete in their IT Challenge 2008 Competition. Today, at the BMW Edge Cinema at Federation Square, Monash held a prize ceremony for this competition. Art of Defence won first place in the Games Development category.
To be honest, I was surprised to win this competition - I had no idea the game would do so well. I wrote the core code for the game back in 2006, when I was in Year 10 (and just having completed Game Design as an elective at school). Art of Defence was written in C++, using DirectX 9.0. Sometime later on, I'll host it on microngamestudios.com for free download, just like I did for NextWar.
I'm not actually sure what the first prize is, but rumour has it that it's a new iPod Nano*. According to Monash, they're having some supply issues so it'll be a few weeks until I get the prize.
Once again, thanks to Mr. Adrian Janson for sponsoring me in the competition, and to the faculty of IT at Monash and to Andrew Owen for their work in setting up the competition. And congratulations to Alan Lahiff, too, who was the other Melbourne High prize winner. He won prizes in the Programming and Database categories, and came second in the running for the IT Challenge Student of the Year. He won a heck of a lot of stuff, so hats off to him!
Anyway, here's a photo of the trophy:

The text reads:
Category
Game Development
1st Place
Adrian Tsai
Melbourne High
* EDIT: I've just recieved an email from Andrew Owen about the prize - first prize in my category recieves a brand new 4GB iPod Nano! According to Wikipedia, I guess that would make it a 4th Gen iPod Nano. I'll also be getting free tickets to IDEF, the International Digital Entertainment Festival, which will be on during the 14th-16th November. Can't wait!
Thursday, September 11, 2008
DMC4 HD Cutscenes For Download
So I was crazy (or stupid) enough to record, encode and host all the cutscenes from Devil May Cry 4 in HD resolution (1280x720).
I've put them up for download here:
http://www.microngamestudios.com/dmc4.html
When added all up, the cutscenes are 1:57:30 long, and approx. 5.2GB. They were recorded from the PC version of the game, with all settings on maximum except for shadows (as the super-high shadow setting is buggy). C8xAA was also turned on for all cutscenes.
I love this game so much. :D
I've put them up for download here:
http://www.microngamestudios.com/dmc4.html
When added all up, the cutscenes are 1:57:30 long, and approx. 5.2GB. They were recorded from the PC version of the game, with all settings on maximum except for shadows (as the super-high shadow setting is buggy). C8xAA was also turned on for all cutscenes.
I love this game so much. :D
Saturday, August 23, 2008
NextWar Download
I've put up NextWar for download. You can get it here:
http://www.microngamestudios.com/nextwar.html
Excuse the horrendous site layout, it's still under construction (and I'm a programmer, not a web artist). :P
http://www.microngamestudios.com/nextwar.html
Excuse the horrendous site layout, it's still under construction (and I'm a programmer, not a web artist). :P
Sunday, August 17, 2008
SwinGame 08 Competition Results
And so ends the SwinGame 08 Game Design Competition. Today, at Swinburne's Hawthorn campus, the results for the competition were announced.
NextWar won first place and I recieved a certificate, a trophy, and a prize of $3000.
NextWar was the result of many months of hard work. I started on NextWar in March, and since then I worked on it almost continuously during my free time. Between school and studying, I devoted what time I could to my pet project. Even though NextWar turned out to be something different to what I had originally intended, and despite a number of small setbacks, I managed to finish and polish NextWar.
There some people I would like to thank: Mr. Adrian Janson, my IT teacher at Melbourne High; my beta testers (Geoff Hong, Julian Taylor, Geoff Wong, Callum Young), who helped me perform balance testing, bug-hunting, and suggested feedback; and finally the SwinGame team as well as the staff and students of Swinburne for creating an awesome game engine and allowing me to create NextWar!
Congratulations to the other prize winners, I hope you all had as much fun as I did.
Over the next week or so, I'll release NextWar publicly for free so that anyone can play it if they so wish. I'll also release the source code as required by the GNU GPL (which SwinGame is licensed under).
The certificate:

And yes, that's a misprint. It's supposed to say 17 August 2008, not 17 August 2007.
The trophy:

The inscription reads:
NextWar won first place and I recieved a certificate, a trophy, and a prize of $3000.
NextWar was the result of many months of hard work. I started on NextWar in March, and since then I worked on it almost continuously during my free time. Between school and studying, I devoted what time I could to my pet project. Even though NextWar turned out to be something different to what I had originally intended, and despite a number of small setbacks, I managed to finish and polish NextWar.
There some people I would like to thank: Mr. Adrian Janson, my IT teacher at Melbourne High; my beta testers (Geoff Hong, Julian Taylor, Geoff Wong, Callum Young), who helped me perform balance testing, bug-hunting, and suggested feedback; and finally the SwinGame team as well as the staff and students of Swinburne for creating an awesome game engine and allowing me to create NextWar!
Congratulations to the other prize winners, I hope you all had as much fun as I did.
Over the next week or so, I'll release NextWar publicly for free so that anyone can play it if they so wish. I'll also release the source code as required by the GNU GPL (which SwinGame is licensed under).
The certificate:

And yes, that's a misprint. It's supposed to say 17 August 2008, not 17 August 2007.
The trophy:

The inscription reads:
SwinGame 08
Computer Game Design
Competition
1st Prize
Team - Micron Game Studios
Computer Game Design
Competition
1st Prize
Team - Micron Game Studios
Tuesday, July 8, 2008
NextWar Progress
After a month-long hiatus from development to focus on exams, I got right back into it a couple of weeks ago. Since the beginning of the holidays, I've been working practically exclusively on NextWar, and great changes have come about.
I had a mid-project change of heart and decided to rethink my concepts for NextWar. After losing a month of development time to school, it was unlikely that I would be able to complete my ambitious plans for NextWar. So I made the decision to reduce the size and scope of the project.
NextWar is no longer an RTS. It will still incorporate a few concepts due to its RTS-based beginnings, but it has switched genres entirely. I'd always been a fan of small time-waster flash games, and one of my favourites was inevitably the Tower Defense genre. I still remember playing the old TD secret mission in Warcraft III - and how much fun it was. And I remember wasting time playing Flash Element TD at 1AM when I should have been doing my school work due the next day. So, at the beginning of the holidays, I made the decision to turn NextWar into a Tower Defense game.
I was at an odd crossroads. A few weeks ago, I had the framework for a game, including a fully-fledged renderer, GUI systems, sound, XML, etc. And very little code was specific to an RTS. So in the end, I never threw away very much code. There's still a lot of old bits and pieces of legacy and deprecated code throughout my codebase, but little effort overall has been wasted.
But the simplicity of a tower defense game in comparison to a fully-fledged RTS has allowed me to fast-track development of the game. NextWar's development cycle is now drawing to a close, as the game's core code is effectively finished after only 2 weeks of development. Now I enter the heady realm of final content creation, testing, evaluation, and bug-fixing.
I had a mid-project change of heart and decided to rethink my concepts for NextWar. After losing a month of development time to school, it was unlikely that I would be able to complete my ambitious plans for NextWar. So I made the decision to reduce the size and scope of the project.
NextWar is no longer an RTS. It will still incorporate a few concepts due to its RTS-based beginnings, but it has switched genres entirely. I'd always been a fan of small time-waster flash games, and one of my favourites was inevitably the Tower Defense genre. I still remember playing the old TD secret mission in Warcraft III - and how much fun it was. And I remember wasting time playing Flash Element TD at 1AM when I should have been doing my school work due the next day. So, at the beginning of the holidays, I made the decision to turn NextWar into a Tower Defense game.
I was at an odd crossroads. A few weeks ago, I had the framework for a game, including a fully-fledged renderer, GUI systems, sound, XML, etc. And very little code was specific to an RTS. So in the end, I never threw away very much code. There's still a lot of old bits and pieces of legacy and deprecated code throughout my codebase, but little effort overall has been wasted.
But the simplicity of a tower defense game in comparison to a fully-fledged RTS has allowed me to fast-track development of the game. NextWar's development cycle is now drawing to a close, as the game's core code is effectively finished after only 2 weeks of development. Now I enter the heady realm of final content creation, testing, evaluation, and bug-fixing.
Tuesday, May 6, 2008
Building the map generator
Progress on NextWar has been steady. I've just completed my mapping algorithms and related code. NextWar will use a simple tile-based system, like almost every other RTS out there. Because NextWar will be based primarily on vector graphics, it may appear odd that I've chosen tile-based for my game. There are real logical and practical reasons for this, though. Tile-based systems have the advantage of being time efficient - at the expense of space (memory). In particular, I had concerns over pathfinding - how would units pathfind through a vector maze? I've only had experience with tile-based pathfinding before, and I've written good heuristic pathfinders before based on existing well-known algorithms. But I've never seen or heard of a vector pathfinding system in any real RTS game. While vector-based systems would allow for much more flexibility, it's also very limited in its practical applications. It really reminds me of arguments of vector graphics vs. rasterised graphics. Vector graphics are extensible and flexible, but slow and sometimes hard to use. That's why I chose to use good old tiles.
So far, I've defined a couple of basic map tiles: grass, dirt, concrete, water, and sand. Like almost everything else in the game, maps are defined through XML files, and can be very easily modified. There are actually no art assets for each tile type - the graphics for each tile are procedurally generated at map load time using custom algorithms. This saves on art costs, ensures that no repetitiveness is seen in the tiles on the map, and spares the world from some of my terrible art skills. I considered adding the functionality of a heightmap to the game, but it was quickly rejected. Being a 2D top-down RTS, it would be difficult to correctly display a real 3D heightmapped map, and as such the player wouldn't even be able to tell differences in terrain height. This is exacerbated by the fact that I'm limiting myself to using vector art for stylistic reasons. In addition, it would complicate gameplay, which is something I'm striving to avoid.
In any RTS you play, you'll find that map tiles and edges are never sharply defined. Instead, they are always blended together and the transition between texture types is always smooth. This is usually done using a technique called texture splatting. However, since all my art is vector graphics, this generally isn't possible. My first mapping attempt resulted, expectedly, in a whole bunch of really visible "blocks" due to the low granularity of the tiles. The solution?
I wrote a smoothing algorithm to automatically round off the sharp corners of the tiles, while at the same time providing an outline surrounding each tile type to make it easier to clearly differentiate between tile types.
This is what it looked like before: (using preliminary test art)

And after, in approximately the same location:

As you can see, the previously sharp corners have been rounded off. In addition, the algorithm accounts for the "cut out" corners, and clips vertices and primitives as required. But as this would leave unsightly gaps in the tiles at the corners, the algorithm also fills in the gaps with the correct tile graphics (which, of course, is all procedurally generated). There were a lot of corner cases in implementing the algorithm (pun intended). For example, points where 3 or 4 tiles could meet needed to be handled separately since the default algorithm simply didn't look good for those cases. Things like map edges, overlapping tile graphics, etc. needed to be handled as well.
Another problem I ran into was that the procedural generation and culling left a lot of unused (orphaned) vertices lying about, and a lot of duplicate vertices which resided in the same place. Removal of orphans was simple, it was just a matter of looping through all the indices and deleting the vertices which were unindexed by the index buffer. But when it came to removing duplicate vertices, I came back to my old friend: the vertex welder. Having had previously written a fast, spatially-partitioned vertex welder for DirectX10 in the past, I'm familiar with the techniques required to "weld" similar vertices together (which eliminates duplicates, saving both memory and time).
However, the techniques I employed in my original C++, DX10 welder were designed for meshes in the range of ~100,000 polygons. Because, at worst, the time complexity for welding could get as bad as O(n^3), I had to use an octree to spatially partition the data into more manageable chunks, and apply the standard O(n^2) algorithm on it. I realised, that with only a few thousand vertices in my map mesh, even a slow brute-force O(n^2) method would likely be fast enough. In a few minutes, I wrote the vertex welder and a quick profile revealed that the vertex welder ran over the entire map mesh in about 10-20ms. This was more than fast enough, and I didn't bother optimising it further (remember, kids, premature optimisation is the root of all evil!).
Now that I've got the mapping algorithms done, I can begin on improving the procedural algorithms to produce some better looking vector art. Since I'm using procedural generation at load time, I can guarantee that no two tiles will look the same if I don't want them to. And, it also means that I can quickly and easily modify the look of entire maps by tweaking a few parameters in code.
So far, I've defined a couple of basic map tiles: grass, dirt, concrete, water, and sand. Like almost everything else in the game, maps are defined through XML files, and can be very easily modified. There are actually no art assets for each tile type - the graphics for each tile are procedurally generated at map load time using custom algorithms. This saves on art costs, ensures that no repetitiveness is seen in the tiles on the map, and spares the world from some of my terrible art skills. I considered adding the functionality of a heightmap to the game, but it was quickly rejected. Being a 2D top-down RTS, it would be difficult to correctly display a real 3D heightmapped map, and as such the player wouldn't even be able to tell differences in terrain height. This is exacerbated by the fact that I'm limiting myself to using vector art for stylistic reasons. In addition, it would complicate gameplay, which is something I'm striving to avoid.
In any RTS you play, you'll find that map tiles and edges are never sharply defined. Instead, they are always blended together and the transition between texture types is always smooth. This is usually done using a technique called texture splatting. However, since all my art is vector graphics, this generally isn't possible. My first mapping attempt resulted, expectedly, in a whole bunch of really visible "blocks" due to the low granularity of the tiles. The solution?
I wrote a smoothing algorithm to automatically round off the sharp corners of the tiles, while at the same time providing an outline surrounding each tile type to make it easier to clearly differentiate between tile types.
This is what it looked like before: (using preliminary test art)

And after, in approximately the same location:

As you can see, the previously sharp corners have been rounded off. In addition, the algorithm accounts for the "cut out" corners, and clips vertices and primitives as required. But as this would leave unsightly gaps in the tiles at the corners, the algorithm also fills in the gaps with the correct tile graphics (which, of course, is all procedurally generated). There were a lot of corner cases in implementing the algorithm (pun intended). For example, points where 3 or 4 tiles could meet needed to be handled separately since the default algorithm simply didn't look good for those cases. Things like map edges, overlapping tile graphics, etc. needed to be handled as well.
Another problem I ran into was that the procedural generation and culling left a lot of unused (orphaned) vertices lying about, and a lot of duplicate vertices which resided in the same place. Removal of orphans was simple, it was just a matter of looping through all the indices and deleting the vertices which were unindexed by the index buffer. But when it came to removing duplicate vertices, I came back to my old friend: the vertex welder. Having had previously written a fast, spatially-partitioned vertex welder for DirectX10 in the past, I'm familiar with the techniques required to "weld" similar vertices together (which eliminates duplicates, saving both memory and time).
However, the techniques I employed in my original C++, DX10 welder were designed for meshes in the range of ~100,000 polygons. Because, at worst, the time complexity for welding could get as bad as O(n^3), I had to use an octree to spatially partition the data into more manageable chunks, and apply the standard O(n^2) algorithm on it. I realised, that with only a few thousand vertices in my map mesh, even a slow brute-force O(n^2) method would likely be fast enough. In a few minutes, I wrote the vertex welder and a quick profile revealed that the vertex welder ran over the entire map mesh in about 10-20ms. This was more than fast enough, and I didn't bother optimising it further (remember, kids, premature optimisation is the root of all evil!).
Now that I've got the mapping algorithms done, I can begin on improving the procedural algorithms to produce some better looking vector art. Since I'm using procedural generation at load time, I can guarantee that no two tiles will look the same if I don't want them to. And, it also means that I can quickly and easily modify the look of entire maps by tweaking a few parameters in code.
Sunday, April 27, 2008
Saturday, April 26, 2008
NextWar - Faction Design
A very preliminary document outlining some of the units, structures and upgrades available to each faction. It's probably going to be changed a lot once I actually get the game done and the factions need to be balanced.
Design - Factions.pdf
Design - Factions.pdf
Friday, April 25, 2008
NextWar - Plot Outline
Next up is a summary of the plot and backstory behind each faction.
NextWar: The Quest for Earth
Design - Plot Outline.pdf
NextWar: The Quest for Earth
Design - Plot Outline.pdf
Thursday, April 24, 2008
Optimising the NextWar loader - why Xml.Serialization is so slow
One of the core design goals of NextWar is that it should function much like a casual game. That means that it needs to satisfy a some criteria for what a user should expect from a casual game. One of these criteria is that it must start and load quickly. Long load times prohibit the "just start and play" factor that you should be able to expect from a casual game.
This was a problem I initially encountered with NextWar. NextWar was designed to be incredibly data-driven. One of the earliest design choices I made was to use an XML-based content definition system for definition practically every aspect of the game. XML-based approaches have been very successful in other games, such as Command and Conquer 3 and Civilization 4. XML is particularly convenient for me because I'm using C# - and as such have access to the massive .NET BCL. One of the most useful set of classes I've found were in Xml.Serialization. Xml.Serialization has the ability to automatically load an XML file and deserialise it into a user-defined class. It also operates in reverse; it can serialise any user type into an XML format. This is useful for things like settings and save games.
When I wrote SCALE, one of the major challenges I faced was this same issue of deserialisation - once I got the data from the file, how did I get it into the data structure? C++ has no automated facilities for this - in the end I resorted to an incredibly long and verbose manual method of copying raw data into specified data members.
Using the power of bytecode, .NET is able to automate the entire process. Seriously, deserialising an XML file takes about 10 lines of code. But, like all things, there is a price to pay for this convenience. Even though I have a very small amount of data (currently about 125KB of XML data), parsing and deserialisation took about 4.5 seconds on a relatively high end 2.8ghz Core 2 Duo. This was insanity - and I knew in advance that I was going to have a LOT more than 125kb of XML by the time I finished the game. The problem was also that all the time was spent in the core .NET libraries themselves - profiling revealed that my code was lightning-fast. The culprit was, unexpectedly enough, Xml.Serialization.
After a lot of in-depth research into the issue, what makes Xml.Serialization so damn slow? The main reason has nothing to do with data conversions, or parsing, or anything like that. The reason is that Xml.Serialization needs to go through a long (and extremely expensive) process to generate the necessary metadata to load the data into your class.
Here's what Xml.Serialization does. It uses the .NET reflection libraries (which, by themselves, are already incredibly slow) to look into the assembly bytecode for the class that you're trying to deserialise. Then, it generates new bytecode from this class so that it can serialise/deserialise each of the data members. In short, it generates a serialiser or deserialiser class on the fly. Once it generates the bytecode for the class, it then compiles that bytecode into a DLL assembly, which is then loaded by the .NET runtime. The .NET JIT1 (just-in-time) compiler then compiles this code and executes it.
All of this is, understandably, extremely slow. Generating an assembly like this could take hundreds of milliseconds for each type. And I know that Xml.Serialization is actually doing this; the Visual Studio debugger confirmed it. But what to do about it?
Well, as it turns out, Microsoft provides a tool with the Visual Studio SDK called SGEN. SGEN does exactly what Xml.Serialization does - except that instead of loading and using the generated DLL, it saves it to file. Thus, it is a tool to pre-generate the serialisers/deserialisers into a DLL which can then be loaded and used directly, rather than letting Xml.Serialization do it at load time.
After a bit of fiddling, I got SGEN to work, and I linked my program against it to use the deserialisers. And lo and behold, my load time was cut in half. Deserialising XML files is now lighting fast, thanks to this handy little tool.
1 It's a common misconception that .NET code is bytecode-interpreted. Such a thing might be fine for a simple scripting language, but would be far too slow for something like .NET. Rather, the .NET runtime includes a Just-In-Time compiler (often referred to as the "JIT"). When the program loads, the JIT reads the bytecode and dynamically compiles it into native assembly instructions. Then, this native assembly is executed directly by the CPU. The nature of the JIT, and the fact that it needs to be done at runtime, means that the assembly code will be nowhere near as fast as an off-line optimising C++ compiler, for example. The JIT is designed to run fast, but it's still not a good idea to be invoking it unless really needed. And in this case of Xml.Serialization, it was certainly not needed.
This was a problem I initially encountered with NextWar. NextWar was designed to be incredibly data-driven. One of the earliest design choices I made was to use an XML-based content definition system for definition practically every aspect of the game. XML-based approaches have been very successful in other games, such as Command and Conquer 3 and Civilization 4. XML is particularly convenient for me because I'm using C# - and as such have access to the massive .NET BCL. One of the most useful set of classes I've found were in Xml.Serialization. Xml.Serialization has the ability to automatically load an XML file and deserialise it into a user-defined class. It also operates in reverse; it can serialise any user type into an XML format. This is useful for things like settings and save games.
When I wrote SCALE, one of the major challenges I faced was this same issue of deserialisation - once I got the data from the file, how did I get it into the data structure? C++ has no automated facilities for this - in the end I resorted to an incredibly long and verbose manual method of copying raw data into specified data members.
Using the power of bytecode, .NET is able to automate the entire process. Seriously, deserialising an XML file takes about 10 lines of code. But, like all things, there is a price to pay for this convenience. Even though I have a very small amount of data (currently about 125KB of XML data), parsing and deserialisation took about 4.5 seconds on a relatively high end 2.8ghz Core 2 Duo. This was insanity - and I knew in advance that I was going to have a LOT more than 125kb of XML by the time I finished the game. The problem was also that all the time was spent in the core .NET libraries themselves - profiling revealed that my code was lightning-fast. The culprit was, unexpectedly enough, Xml.Serialization.
After a lot of in-depth research into the issue, what makes Xml.Serialization so damn slow? The main reason has nothing to do with data conversions, or parsing, or anything like that. The reason is that Xml.Serialization needs to go through a long (and extremely expensive) process to generate the necessary metadata to load the data into your class.
Here's what Xml.Serialization does. It uses the .NET reflection libraries (which, by themselves, are already incredibly slow) to look into the assembly bytecode for the class that you're trying to deserialise. Then, it generates new bytecode from this class so that it can serialise/deserialise each of the data members. In short, it generates a serialiser or deserialiser class on the fly. Once it generates the bytecode for the class, it then compiles that bytecode into a DLL assembly, which is then loaded by the .NET runtime. The .NET JIT1 (just-in-time) compiler then compiles this code and executes it.
All of this is, understandably, extremely slow. Generating an assembly like this could take hundreds of milliseconds for each type. And I know that Xml.Serialization is actually doing this; the Visual Studio debugger confirmed it. But what to do about it?
Well, as it turns out, Microsoft provides a tool with the Visual Studio SDK called SGEN. SGEN does exactly what Xml.Serialization does - except that instead of loading and using the generated DLL, it saves it to file. Thus, it is a tool to pre-generate the serialisers/deserialisers into a DLL which can then be loaded and used directly, rather than letting Xml.Serialization do it at load time.
After a bit of fiddling, I got SGEN to work, and I linked my program against it to use the deserialisers. And lo and behold, my load time was cut in half. Deserialising XML files is now lighting fast, thanks to this handy little tool.
1 It's a common misconception that .NET code is bytecode-interpreted. Such a thing might be fine for a simple scripting language, but would be far too slow for something like .NET. Rather, the .NET runtime includes a Just-In-Time compiler (often referred to as the "JIT"). When the program loads, the JIT reads the bytecode and dynamically compiles it into native assembly instructions. Then, this native assembly is executed directly by the CPU. The nature of the JIT, and the fact that it needs to be done at runtime, means that the assembly code will be nowhere near as fast as an off-line optimising C++ compiler, for example. The JIT is designed to run fast, but it's still not a good idea to be invoking it unless really needed. And in this case of Xml.Serialization, it was certainly not needed.
Friday, April 18, 2008
NextWar: The Quest for Earth
"NextWar" is such a nice generic name, isn't it?
Well, it's pretty much official now. I've joined the SwinGame game competition.
SwinGame
SwinGame is an API written by the staff and students of Swinburne University, based here in Melbourne, Australia. Swinburne is also backing the SwinGame 08 Competition - where Australian Year 11 and Year 12 students can participate in a competition to create the best overall game using the SwinGame API.
The grand prize is $3000 for the author of the game. Second prize is $2000 and third prize is $1000.
Since I happen to be an Australian student currently studying in Year 12, I'm entering this contest. Hopefully, come August this year, I'll be walking away with $3000.
NextWar
NextWar is what I decided to name my game. It came to me while sitting on the train, which is where I also formulated the basic game mechanics and plot structure. NextWar's full name is "NextWar: The Quest for Earth". It's going to be a 2D RTS game, written in C# and using the SwinGame API.
For more information, I'll be posting progress reports here, as well as here to this blog.
So far, I've got the basic framework for the game done; gamestate management and GUI are all complete, as well as the asset loading system and basic renderer.
Also, I've been doing some design for the actual game itself. I've been writing some documents for my own personal use regarding the design of the game. I decided to post them here; they're not very interesting and not particularly well done, but they function as an effective brain-dump for ideas. And it couldn't hurt to post them online. I never intended for them to be seen by anyone other than me, so sorry if they don't make much sense.
So, without further ado, the first in a series of documents I'll be posting:
NextWar: The Quest for Earth
Design - Basic Overview & Gameplay
Well, it's pretty much official now. I've joined the SwinGame game competition.
SwinGame
SwinGame is an API written by the staff and students of Swinburne University, based here in Melbourne, Australia. Swinburne is also backing the SwinGame 08 Competition - where Australian Year 11 and Year 12 students can participate in a competition to create the best overall game using the SwinGame API.
The grand prize is $3000 for the author of the game. Second prize is $2000 and third prize is $1000.
Since I happen to be an Australian student currently studying in Year 12, I'm entering this contest. Hopefully, come August this year, I'll be walking away with $3000.
NextWar
NextWar is what I decided to name my game. It came to me while sitting on the train, which is where I also formulated the basic game mechanics and plot structure. NextWar's full name is "NextWar: The Quest for Earth". It's going to be a 2D RTS game, written in C# and using the SwinGame API.
For more information, I'll be posting progress reports here, as well as here to this blog.
So far, I've got the basic framework for the game done; gamestate management and GUI are all complete, as well as the asset loading system and basic renderer.
Also, I've been doing some design for the actual game itself. I've been writing some documents for my own personal use regarding the design of the game. I decided to post them here; they're not very interesting and not particularly well done, but they function as an effective brain-dump for ideas. And it couldn't hurt to post them online. I never intended for them to be seen by anyone other than me, so sorry if they don't make much sense.
So, without further ado, the first in a series of documents I'll be posting:
NextWar: The Quest for Earth
Design - Basic Overview & Gameplay
Thursday, April 3, 2008
Optimising the Vertex Welder: Adventures Into Spatial Partitioning
Vertex welding is simply an optimisation technique to reduce the number of vertices sent to the graphics hardware. It's very simple: if there there are two vertices which are very close to each other, then the two vertices are "welded" into a single vertex. Since the vertices were so close together in the first place, nobody ever notices and we just saved ourselves a vertex.
Really, vertex welding is just a specialised form of collision detection. Each vertex needs to be checked against every other vertex to see if they're close together or not (and welded if they are). As such, a naive implementation runs in O(n^2) (or worse) time.
The first vertex welder I wrote was, well, slow. Welding a ~22,000 vertex mesh took over 12 seconds, and welding a smaller ~2300 vertex mesh took about 300ms. This was a completely unacceptable running time, as meshes are expected to run in the range of tens of thousands of vertices and a multi-minute loading time would be pure insanity.
That vertex welder was a very simple implementation: for each vertex, search every other vertex and weld if needed. If a weld occurred, then scan through the index buffer and make the necessary corrections. At worst, this algorithm ran in O(n^3) time, because it would need to loop through the index buffer each time a vertex was welded (and the index buffer's size for a freshly loaded COLLADA mesh is directly proportional to vertex count). At best, it was O(n^2).
I dumped that code and rewrote it from scratch, trading more memory usage for a better running time. I kept buffers which mapped vertices to welded vertices, and used this in a final, single loop over the index buffer to correct the indices. This brought the running time down to O((n^2+n)/2) (rather than between O(n^2) and O(n^3) like the old code). This dramatically improved running time: that 22,000 vertex mesh that took 12 seconds to load on the old code? 1.9 seconds on the new code.
Running the code through a profiler revealed a few performance hotspots. At the top of the list was an incredibly expensive square root that was being used in the distance calculations. Factoring out the square root and making some misc. performance changes increased the performance by a factor of 4.
But the algorithm was still too slow, O((n^2+n)/2) wasn't good enough. I needed to see if it would be possible to get it any faster. Rather than pine over micro optimisations in the code I had, I instead looked for a high-level algorithmic change.
The most common optimisation for dumb collision detection is spatial partitioning. Spatial partitioning involves splitting up the entities into groups based on their position. There are many constructs to achieve this, such as BSP trees and kd-trees.
I chose to use an octree. Octrees are a special case of kd-trees. Specifically, octrees are 3-dimensional kd-trees (and quadtrees are 2-dimensional kd-trees). Octrees are simple: divide up the search space into 8, equally sized, "octants". Each octant represents an eighth of the volume of the search space. Then for each octant, recursively split it into smaller and smaller octants until a desired limit is reached.
This diagram, courtesy of wikipedia, demonstrates nicely:
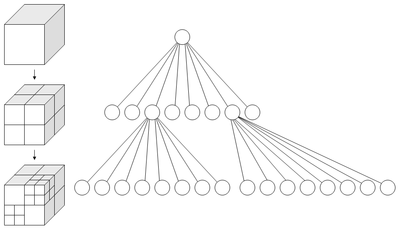
After the octree is constructed and all the vertices are divided into neat little groups based on spatial position, the welding can begin. Welding the mesh then simply consists of going through each octant in the octree, and welding the octant's vertices. Since the number of vertices in each octant is much smaller than the original, the welding is done much faster.
Usage of an octree reduces the time complexity from O(n^2) to average O(m(n / m)^2), where n is the total number of vertices and m is the total number of partitions in the octree. This can be simplified down to simply O(n^2/m). But what to choose for m? In other words, how many partitions should we create in the octree?
I chose a value of (sqrt(n) / 4). Why? No idea. It's a magic number, and it worked reasonably well. sqrt(n) would mean that the average number of vertices in each partition would be equal to the number of partitions. But the more partitions you create, the more overhead the octree has. But if you have too few partitions, the welding's going to take too long for each partition. It's a fine balance, and sqrt(n) / 4 seemed to work well.
This means that, when using the octree, the vertex welding algorithm is not quite O(n) linear time, but it's certainly a lot better than O(n^2). Here are the benchmark times:
As you can see, using the octree has resulted in a very significant improvement in speed. Completely welding a 100,000 vertex sphere now takes only 686ms compared to 489484ms, which is in excess of a 700x improvement in speed.
Really, vertex welding is just a specialised form of collision detection. Each vertex needs to be checked against every other vertex to see if they're close together or not (and welded if they are). As such, a naive implementation runs in O(n^2) (or worse) time.
The first vertex welder I wrote was, well, slow. Welding a ~22,000 vertex mesh took over 12 seconds, and welding a smaller ~2300 vertex mesh took about 300ms. This was a completely unacceptable running time, as meshes are expected to run in the range of tens of thousands of vertices and a multi-minute loading time would be pure insanity.
That vertex welder was a very simple implementation: for each vertex, search every other vertex and weld if needed. If a weld occurred, then scan through the index buffer and make the necessary corrections. At worst, this algorithm ran in O(n^3) time, because it would need to loop through the index buffer each time a vertex was welded (and the index buffer's size for a freshly loaded COLLADA mesh is directly proportional to vertex count). At best, it was O(n^2).
I dumped that code and rewrote it from scratch, trading more memory usage for a better running time. I kept buffers which mapped vertices to welded vertices, and used this in a final, single loop over the index buffer to correct the indices. This brought the running time down to O((n^2+n)/2) (rather than between O(n^2) and O(n^3) like the old code). This dramatically improved running time: that 22,000 vertex mesh that took 12 seconds to load on the old code? 1.9 seconds on the new code.
Running the code through a profiler revealed a few performance hotspots. At the top of the list was an incredibly expensive square root that was being used in the distance calculations. Factoring out the square root and making some misc. performance changes increased the performance by a factor of 4.
But the algorithm was still too slow, O((n^2+n)/2) wasn't good enough. I needed to see if it would be possible to get it any faster. Rather than pine over micro optimisations in the code I had, I instead looked for a high-level algorithmic change.
The most common optimisation for dumb collision detection is spatial partitioning. Spatial partitioning involves splitting up the entities into groups based on their position. There are many constructs to achieve this, such as BSP trees and kd-trees.
I chose to use an octree. Octrees are a special case of kd-trees. Specifically, octrees are 3-dimensional kd-trees (and quadtrees are 2-dimensional kd-trees). Octrees are simple: divide up the search space into 8, equally sized, "octants". Each octant represents an eighth of the volume of the search space. Then for each octant, recursively split it into smaller and smaller octants until a desired limit is reached.
This diagram, courtesy of wikipedia, demonstrates nicely:
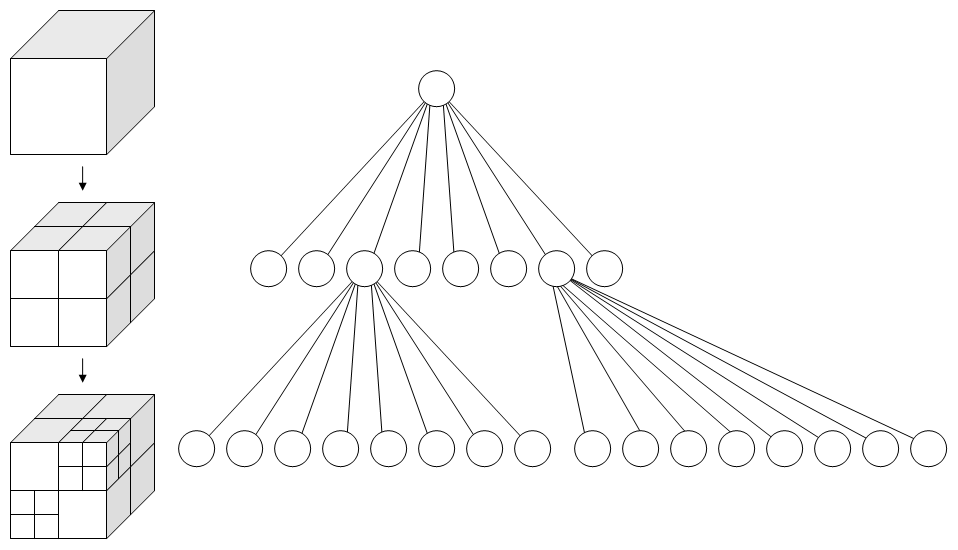
After the octree is constructed and all the vertices are divided into neat little groups based on spatial position, the welding can begin. Welding the mesh then simply consists of going through each octant in the octree, and welding the octant's vertices. Since the number of vertices in each octant is much smaller than the original, the welding is done much faster.
Usage of an octree reduces the time complexity from O(n^2) to average O(m(n / m)^2), where n is the total number of vertices and m is the total number of partitions in the octree. This can be simplified down to simply O(n^2/m). But what to choose for m? In other words, how many partitions should we create in the octree?
I chose a value of (sqrt(n) / 4). Why? No idea. It's a magic number, and it worked reasonably well. sqrt(n) would mean that the average number of vertices in each partition would be equal to the number of partitions. But the more partitions you create, the more overhead the octree has. But if you have too few partitions, the welding's going to take too long for each partition. It's a fine balance, and sqrt(n) / 4 seemed to work well.
This means that, when using the octree, the vertex welding algorithm is not quite O(n) linear time, but it's certainly a lot better than O(n^2). Here are the benchmark times:
~2,000 Vertex Ducky:
Original: 306ms
Profiled + Reoptimised + Octree: [Too fast to measure]
~12,000 Vertex Torus
Profiled + Reoptimised: 4181ms
Profiled + Reoptimised + Octree: 46ms
~22,000 Vertex Lunar Rover:
Original: 12768ms
Optimised: 1966ms
Profiled + Reoptimised: 468ms
Profiled + Reoptimised + Octree: 47ms
100,000 Vertex Sphere:
Profiled + Reoptimised: 489484ms
Profiled + Reoptimised + Octree: 686ms
As you can see, using the octree has resulted in a very significant improvement in speed. Completely welding a 100,000 vertex sphere now takes only 686ms compared to 489484ms, which is in excess of a 700x improvement in speed.
Wednesday, April 2, 2008
Debugging Horrors: The case of the rogue #pragma pack
Here's a tale of horrors of #pragma pack. I already posted quite a bit about the issue over on that thread at GameDev.Net, so I won't bother reposting it here. It's an interesting read into solving a particular, very strange, bug.
The gist of the issue was that I forgot to disable a particular #pragma pack in one of my headers - causing the packing rules to propogate down into the FCollada header files. Because of this, the compiler got the padding and offsets wrong, which resulted in corrupted this pointers all over the place.
It was, by far, my most harrowing debugging experience. However, it was an experience not to be forgotten. And it was an excellent showcase for Visual Studio's amazing debugging capabilities. I'm not kidding here; Visual Studio has the best and easiest to use debugger ever. Period. I really doubt I could have resolved this bug without the awesome debugger in VS.
But, my crashing problems were still not resolved. Even after I fixed that rogue #pragma pack, the code ran fine in Debug mode. But crashed in Release mode. Since I couldn't really use the debugger in release mode, I had no idea what was going on. The capabilities of the debugger are castrated in release mode, since release mode is supposed to be for final production-level code, and has no debugging facilities.
All I knew was that the crash was occurring even before WinMain() was hit. Which meant that something funky was going on. The debugger did still help, even though was in release mode. The code that was causing the crash was a static variable in one of FCollada's classes: a tree class of some sort.
A quick look at the code in the tree class revealed this little fact: the constructor of the tree class allocated some memory through a global memory handler. The global memory handler was just a global variable, a function pointer, that was initialised to malloc/free. Whenever an allocation was made, this function pointer would be used to allocate memory.
Experienced programmers should see the bug. It's a very subtle way to crash your program, and is difficult to track down. It's known as the Static Initialisation Order Fiasco. Global variables do not have a defined order of initialisation in C++ - it all depends on how the compiler was feeling that day. In other words, initialisation order is effectively random.
So what was actually happening? Well, the global tree variable was being initialised before the memory manager was. That meant that in the constructor for the tree, it was trying to allocate some memory. But since the memory manager hadn't even been initialised yet, the entire program crashed before it had even hit main()!
Up to this point, everyone had just gotten lucky. The compiler had, for some reason, decided to always intitialise the memory manager first. So the memory manager was initialised and ready to go by the time the tree was constructed. But when I recompiled the code, my compiler decided to do it in the reverse order which crashed the program with a difficult-to-detect bug.
This is one of the things that makes globals so damn dangerous - the static initialisation order fiasco gives your program a 50/50 percent chance of dying. And it's random. As the C++ FAQ Lite deftly noted, it's like playing russian roulette with half the chambers loaded.
Needless to say, I left a post informing the developers about it and posted a fix. FCollada is no longer managed by Feeling Software; they relegated the responsibility to the open source community. It remains to be seen whether they'll actually fix this bug, but I'm not hopeful. In the meantime, I've fixed the bug on my local copy of the source code, and now my COLLADA loader is working fine.
Stay tuned for next time: Optimising the mesh loader.
The gist of the issue was that I forgot to disable a particular #pragma pack in one of my headers - causing the packing rules to propogate down into the FCollada header files. Because of this, the compiler got the padding and offsets wrong, which resulted in corrupted this pointers all over the place.
It was, by far, my most harrowing debugging experience. However, it was an experience not to be forgotten. And it was an excellent showcase for Visual Studio's amazing debugging capabilities. I'm not kidding here; Visual Studio has the best and easiest to use debugger ever. Period. I really doubt I could have resolved this bug without the awesome debugger in VS.
But, my crashing problems were still not resolved. Even after I fixed that rogue #pragma pack, the code ran fine in Debug mode. But crashed in Release mode. Since I couldn't really use the debugger in release mode, I had no idea what was going on. The capabilities of the debugger are castrated in release mode, since release mode is supposed to be for final production-level code, and has no debugging facilities.
All I knew was that the crash was occurring even before WinMain() was hit. Which meant that something funky was going on. The debugger did still help, even though was in release mode. The code that was causing the crash was a static variable in one of FCollada's classes: a tree class of some sort.
A quick look at the code in the tree class revealed this little fact: the constructor of the tree class allocated some memory through a global memory handler. The global memory handler was just a global variable, a function pointer, that was initialised to malloc/free. Whenever an allocation was made, this function pointer would be used to allocate memory.
Experienced programmers should see the bug. It's a very subtle way to crash your program, and is difficult to track down. It's known as the Static Initialisation Order Fiasco. Global variables do not have a defined order of initialisation in C++ - it all depends on how the compiler was feeling that day. In other words, initialisation order is effectively random.
So what was actually happening? Well, the global tree variable was being initialised before the memory manager was. That meant that in the constructor for the tree, it was trying to allocate some memory. But since the memory manager hadn't even been initialised yet, the entire program crashed before it had even hit main()!
Up to this point, everyone had just gotten lucky. The compiler had, for some reason, decided to always intitialise the memory manager first. So the memory manager was initialised and ready to go by the time the tree was constructed. But when I recompiled the code, my compiler decided to do it in the reverse order which crashed the program with a difficult-to-detect bug.
This is one of the things that makes globals so damn dangerous - the static initialisation order fiasco gives your program a 50/50 percent chance of dying. And it's random. As the C++ FAQ Lite deftly noted, it's like playing russian roulette with half the chambers loaded.
Needless to say, I left a post informing the developers about it and posted a fix. FCollada is no longer managed by Feeling Software; they relegated the responsibility to the open source community. It remains to be seen whether they'll actually fix this bug, but I'm not hopeful. In the meantime, I've fixed the bug on my local copy of the source code, and now my COLLADA loader is working fine.
Stay tuned for next time: Optimising the mesh loader.
Friday, March 28, 2008
SCALE III, part 4
The SCALE API is as simple as it gets. It consists of just two functions: ParseFromFiles() and ParseFromMemory(). The ParseFromFiles() function takes an array of filenames, loads the files into memory, and passes them to ParseFromMemory().
ParseFromMemory() itself takes an array of strings, each string in the array represents a translation unit. Inside ParseFromMemory(), the SCALE engine is initialised and parsing occurs.
The SCALE Engine has 2 distinct stages: tokenisation and parsing.
Tokenisation
Tokenisation of a translation unit is the process of breaking up the entire translation unit into separate entities known as "lexemes". A lexeme is the smallest "unit" that SCALE understands - they are analogous to words in english.
In English, lexemes (eg, "run", "play", "discombobulate") are delimited by whitespace. That means, lexemes (or words) are defined to be separated by whitespace - if there's a bunch of characters that aren't separated by whitespace, it's considered to be a single word.
I'm sure that I'm about to be mob lynched by all the linguists out there, so I think I'll stop with the analogies to real languages. In SCALE, lexemes are delimited by a certain number of characters which where described in part 2 of this series. It's the tokeniser's job to break apart the entire translation unit into lexemes that then go into the parsing stage. For example, let's say we have the following translation unit:
The tokeniser would break up that code into the following list of tokens:
As you can see, whitespace and comments are ignored - only the useful information is extracted. This list of tokens is then passed to the parser.
Parsing
The job of the parser is to make sense of the raw tokens given to it by the tokeniser. At its core, the SCALE parser's job is to check syntax and format/convert the information into useful data structures. The parser is responsible for type checking, syntax & formatting, and conversion of data. The parser just sequentially runs through each token in the list, and performs checking to ensure that it's correct. If an unexpected token is found (eg. missing an opening brace), the parser errors out. When parsing object types, object names, modules, variable names and variable values, the parser does checks to ensure the validity of the token and enforces things like naming rules and types.
The output of the parser is a large associative data structure (a std::map<>, specifically) called ParsedData. The ParsedData structure contains all the types which were parsed by the parser. ParsedData is a std::map whose key is a type name, and whose key values is a data structure called TypeData.
The TypeData structure contains all the parsed objects that are of the specified type. It, too, is a std::map associative container. The key value is an object name, and the key value type is a structure called ObjectData.
The ObjectData structure contains all the modules contained in a particular object. Like the other data structures, this is another associative container (std::map). The key is a module name, and the key value is an array of "ModuleData" data structures (remember, it's legal to have multiple modules of the same name in an object).
The ModuleData structure finally contains a map of all the variables in that module. The map's key is a variable name, the value is a VariableData structure.
Finally, the VariableData structure contains the data for a variable, including the type.
If you didn't understand that, here's a helpful diagram that may help:

Performance
SCALE III, as the name implies, is the third time I've attempted to implement SCALE. The first iteration was, well, terrible. It was slow and incredibly fragile with overly strict and verbose syntax. It was abandoned quite quickly, and SCALE II was born. SCALE II had the exact same syntax and naming/typing rules as SCALE III, but it's impementation was very different. SCALE II was an attempt at single-pass lexical analysis. There was no tokenisation or parsing or compiling phase, it was all done in-place. And it was a bloated, slow, complex piece of code. I had believed that I could save some performance by making it single pass - but it was a lot more difficult than I would have imagined. That's why SCALE III is done in two passes, like a lot of other lexers out there.
SCALE II relied heavily on simple arrays to store data - and searching arrays was pretty slow as it was an O(n) operation. For namespace collisions and type checking, this resulted in a terrible O(n^2) running time. SCALE III now relies on sorted associative arrays: std::map is usually implemented as a binary red-black tree and it guarantees O(log n) time complexity when searching, indexing, inserting and removing from the tree. Thanks to this, large portions of the engine were optimised from O(n^2) running time to O(n log n), which is a very significant improvement.
SCALE III also supports multithreaded processing of translation units (well, SCALE II did as well, but it wasn't quite as robust). Since translation units can be processed separately, they are dispatched to a thread pool where they are processed in parallel. Since name resolution and checking across translation unit boundaries requires that all the information be available, it's delayed until all translation units have been processed. Then, the thread pool is destructed and namespace resolution occurs on a single thread. That means that some of the processing is required to be serial, but the majority of processing (tokenisation, most of the parser) can be run in parallel for a significant performance increase over single-threaded processing.
Here are some benchmark results on my processor (Core 2 Duo E6600):
With multithreading on, the total running time is reduced by 43%. That means that with multithreading on, SCALE is over 76% faster! Of course, I only have a dual core to test it on. The gains would be even larger on a quad core, or octo core. This multithreaded system is scalable up to the number of translation units available, so benefits would likely be seen up to 16-core and beyond, given that there's likely to be a large number of translation units.
Of course, it certainly could be faster. I haven't even run SCALE through a profiler yet, since there's practically no need to optimise. In any sane, non-pathological real-world case, we'd be looking at miniscule amounts of data. At most, maybe 1mb of text data spread out across dozens of files. Since the loading is faster on lots of small files as opposed to a couple of large files, SCALE can parse an entire game's worth of data almost instantly.
ParseFromMemory() itself takes an array of strings, each string in the array represents a translation unit. Inside ParseFromMemory(), the SCALE engine is initialised and parsing occurs.
The SCALE Engine has 2 distinct stages: tokenisation and parsing.
Tokenisation
Tokenisation of a translation unit is the process of breaking up the entire translation unit into separate entities known as "lexemes". A lexeme is the smallest "unit" that SCALE understands - they are analogous to words in english.
In English, lexemes (eg, "run", "play", "discombobulate") are delimited by whitespace. That means, lexemes (or words) are defined to be separated by whitespace - if there's a bunch of characters that aren't separated by whitespace, it's considered to be a single word.
I'm sure that I'm about to be mob lynched by all the linguists out there, so I think I'll stop with the analogies to real languages. In SCALE, lexemes are delimited by a certain number of characters which where described in part 2 of this series. It's the tokeniser's job to break apart the entire translation unit into lexemes that then go into the parsing stage. For example, let's say we have the following translation unit:
Type ObjectName
{
~Frobnicate
{
Foo = 5;
}
}
The tokeniser would break up that code into the following list of tokens:
Lexeme Index Row, Column
"Type" 0 1, 1
"ObjectName" 5 1, 6
"{" 17 2, 1
"~Frobnicate" 24 3, 5
"{" 41 4, 5
"Foo" 52 5, 9
"=" 56 5, 13
"5" 58 5, 15
";" 59 5, 16
"}" 66 6, 5
"}" 69 7, 1
As you can see, whitespace and comments are ignored - only the useful information is extracted. This list of tokens is then passed to the parser.
Parsing
The job of the parser is to make sense of the raw tokens given to it by the tokeniser. At its core, the SCALE parser's job is to check syntax and format/convert the information into useful data structures. The parser is responsible for type checking, syntax & formatting, and conversion of data. The parser just sequentially runs through each token in the list, and performs checking to ensure that it's correct. If an unexpected token is found (eg. missing an opening brace), the parser errors out. When parsing object types, object names, modules, variable names and variable values, the parser does checks to ensure the validity of the token and enforces things like naming rules and types.
The output of the parser is a large associative data structure (a std::map<>, specifically) called ParsedData. The ParsedData structure contains all the types which were parsed by the parser. ParsedData is a std::map whose key is a type name, and whose key values is a data structure called TypeData.
The TypeData structure contains all the parsed objects that are of the specified type. It, too, is a std::map associative container. The key value is an object name, and the key value type is a structure called ObjectData.
The ObjectData structure contains all the modules contained in a particular object. Like the other data structures, this is another associative container (std::map). The key is a module name, and the key value is an array of "ModuleData" data structures (remember, it's legal to have multiple modules of the same name in an object).
The ModuleData structure finally contains a map of all the variables in that module. The map's key is a variable name, the value is a VariableData structure.
Finally, the VariableData structure contains the data for a variable, including the type.
If you didn't understand that, here's a helpful diagram that may help:
Performance
SCALE III, as the name implies, is the third time I've attempted to implement SCALE. The first iteration was, well, terrible. It was slow and incredibly fragile with overly strict and verbose syntax. It was abandoned quite quickly, and SCALE II was born. SCALE II had the exact same syntax and naming/typing rules as SCALE III, but it's impementation was very different. SCALE II was an attempt at single-pass lexical analysis. There was no tokenisation or parsing or compiling phase, it was all done in-place. And it was a bloated, slow, complex piece of code. I had believed that I could save some performance by making it single pass - but it was a lot more difficult than I would have imagined. That's why SCALE III is done in two passes, like a lot of other lexers out there.
SCALE II relied heavily on simple arrays to store data - and searching arrays was pretty slow as it was an O(n) operation. For namespace collisions and type checking, this resulted in a terrible O(n^2) running time. SCALE III now relies on sorted associative arrays: std::map is usually implemented as a binary red-black tree and it guarantees O(log n) time complexity when searching, indexing, inserting and removing from the tree. Thanks to this, large portions of the engine were optimised from O(n^2) running time to O(n log n), which is a very significant improvement.
SCALE III also supports multithreaded processing of translation units (well, SCALE II did as well, but it wasn't quite as robust). Since translation units can be processed separately, they are dispatched to a thread pool where they are processed in parallel. Since name resolution and checking across translation unit boundaries requires that all the information be available, it's delayed until all translation units have been processed. Then, the thread pool is destructed and namespace resolution occurs on a single thread. That means that some of the processing is required to be serial, but the majority of processing (tokenisation, most of the parser) can be run in parallel for a significant performance increase over single-threaded processing.
Here are some benchmark results on my processor (Core 2 Duo E6600):
2x 7.5mb files (15mb total), MT OFF: 6505ms
2x 7.5mb files (15mb total), MT ON: 3679ms
With multithreading on, the total running time is reduced by 43%. That means that with multithreading on, SCALE is over 76% faster! Of course, I only have a dual core to test it on. The gains would be even larger on a quad core, or octo core. This multithreaded system is scalable up to the number of translation units available, so benefits would likely be seen up to 16-core and beyond, given that there's likely to be a large number of translation units.
Of course, it certainly could be faster. I haven't even run SCALE through a profiler yet, since there's practically no need to optimise. In any sane, non-pathological real-world case, we'd be looking at miniscule amounts of data. At most, maybe 1mb of text data spread out across dozens of files. Since the loading is faster on lots of small files as opposed to a couple of large files, SCALE can parse an entire game's worth of data almost instantly.
Monday, March 24, 2008
SCALE III, part 3
The Type System
Variables in SCALE do not have types, unlike objects (eg. an object "SpriteMaterial" having a type of "Material"). Or not explicit types, anyway. The user does not specify the type of a variable. Nor does the application, for that matter. A variable can have any type, and this type is determined at runtime by the SCALE parser. There are 12 fundamental types that SCALE recognises:
When a variable's value is parsed, the type is dynamically determined based on a set of rules. Right now, the rules are a bit arbitrary and will need to be formalised and set in stone sometime in the future. But for now, this the general algorithm:
Once SCALE determines the type, it converts it into a binary format and gives it to the application. It is the application's job to determine what to do with it, and what to do if the type isn't what was expected.
Naming
In SCALE, each object must have a unique name. That is, it is illegal for two objects to share a name.
Each type has its own namespace. Which means that the unique name requirement doesn't carry between two different types. For example: it's legal to have an object of type "Foo" to be called "Fred", and at the same time to have an object of type "Bar" to also be called "Fred". This is legal:
There's a gotcha, though. You'd expect that each translation unit would get its own namespace, but it doesn't work that way. All translation units share the same, global namespace. Meaning that separating two identically typed, identically named objects into two different translation units (or files) won't work.
This unique name rule doesn't apply to modules in an object - it is legal to have two modules of the same name (and even containing the same data, if you wanted). This is legal:
The rule rears its ugly head again when dealing with variables. Every module, in every object, gets its own namespace. What that means is that in any particular module, you're not allowed to have two variables with the same name. However, you are obviously allowed to have two variables with the same value. For example, the following is NOT legal, and will cause an error during parse time:
That's about it as far as naming and type rules go - it's relatively simple and easy to remember.
Next time, I'll talk about the usage of the SCALE API from the perspective of the application, and how it's going to be used with SolSector.
Variables in SCALE do not have types, unlike objects (eg. an object "SpriteMaterial" having a type of "Material"). Or not explicit types, anyway. The user does not specify the type of a variable. Nor does the application, for that matter. A variable can have any type, and this type is determined at runtime by the SCALE parser. There are 12 fundamental types that SCALE recognises:
- Integer
- Boolean
- Float
- Reference
- Enumeration
- String
- IntegerArray
- BooleanArray
- FloatArray
- ReferenceArray
- EnumerationArray
- StringArray
When a variable's value is parsed, the type is dynamically determined based on a set of rules. Right now, the rules are a bit arbitrary and will need to be formalised and set in stone sometime in the future. But for now, this the general algorithm:
- If the value is surrounded by braces ('{' and '}'), it is an array. For each element, use this algorithm to determine the type.1
- Else, if the value is surrounded by quotes ('"'), it is of type String
- Else, If the value is preceeded by an ampersand ('&'), it is of type Reference
- Else, If the value is "true" or "false" (sans quotes), it is of type Boolean.
- Else, if the value is a numeric value2
- If the value has a decimal point ('.'), it is a Float
- Else, the value is an Integer
- Else, it is of type Enumeration.
1 Arrays must be homogeneous; that is, the types of all elements must be identical. Arrays of arrays are not supported.
2 Determination of whether a value is "numeric" is currently a bit arbitrary. Needs to be finalised in the future.
Once SCALE determines the type, it converts it into a binary format and gives it to the application. It is the application's job to determine what to do with it, and what to do if the type isn't what was expected.
Naming
In SCALE, each object must have a unique name. That is, it is illegal for two objects to share a name.
Each type has its own namespace. Which means that the unique name requirement doesn't carry between two different types. For example: it's legal to have an object of type "Foo" to be called "Fred", and at the same time to have an object of type "Bar" to also be called "Fred". This is legal:
Bar Fred
{
}
Foo Fred
{
}
There's a gotcha, though. You'd expect that each translation unit would get its own namespace, but it doesn't work that way. All translation units share the same, global namespace. Meaning that separating two identically typed, identically named objects into two different translation units (or files) won't work.
This unique name rule doesn't apply to modules in an object - it is legal to have two modules of the same name (and even containing the same data, if you wanted). This is legal:
Type ObjectName
{
~Frobnicate
{
Foo = 5;
}
~Frobnicate
{
Foo = 6;
}
}
The rule rears its ugly head again when dealing with variables. Every module, in every object, gets its own namespace. What that means is that in any particular module, you're not allowed to have two variables with the same name. However, you are obviously allowed to have two variables with the same value. For example, the following is NOT legal, and will cause an error during parse time:
Type Wilma
{
~Fred
{
Foo = 5;
Foo = 6;
}
}
That's about it as far as naming and type rules go - it's relatively simple and easy to remember.
Next time, I'll talk about the usage of the SCALE API from the perspective of the application, and how it's going to be used with SolSector.
Sunday, March 23, 2008
SCALE III, part 2
So what the heck does it even do? What does it look like?
SCALE defines a syntax format and provides a parser for that syntax. That's basically all that SCALE is. As I mentioned in my previous post, SCALE was inspired by and is based upon the .ini configuration files of Command and Conquer: Generals. A key feature of C&C:G's .ini system was its devilish simplicity. The syntax was simple and easy to understand - they were, after all, just configuration files (hence the .ini extension).
So here's what the syntax of SCALE looks like:
As you can see, the syntax is really simple. It's broken up into a simple hierarchy:
At the top, you have translation units. They're analogous to C/C++ translation or compilation units, in that they are effectively separate "modules". Each translation unit can be parsed without needing to look at any other translation units.
Each translation unit is typically represented by a file, but no limitation is imposed by the parser. Inside each translation unit is any arbitrary number of objects. Each object can be of any arbitrary type. Each object can also hold an arbitrary number of modules. And each module can hold an arbitrary number of arbitrarily typed variables with arbitrary values.
Confused? Let's take another look at the syntax we saw above. That code is actually an entire object - named "SpriteMaterial". The type of this object is a "Material". This works the same way as declaring variables C/C++: declare a type, then the variable name. In the body of the object, you are allowed any number of modules. A module is signified by the tilde prefix ('~'). For example, there are 4 modules in the above object: "Shader", "ShaderPass", "ShaderConstants", and "Texture". SCALE allows any number of modules, and they can have any name. SCALE also allows duplicate named modules - for example, it is legal to declare two modules named "Texture". Inside each module is a set of variables. SCALE also allows any number of variables, and they can be named however the application wishes.
Two types of comments are supported in SCALE: C-style comments and C++ style comments. Comments are merely skipped by the parser. They act just like they do in C++:
Like in many languages, whitespace is mostly irrelevant in SCALE and has no syntactic meaning. Tokens in SCALE are delimited by a few things:
- Comments
- Braces
- Newlines
- Whitespace
- Semicolon
- Equals sign
That means that you can separate two identifiers with any of the above constructs. For example: this is entirely legal:
It's just unreadable, that's all.
So that's the syntax of SCALE. Very easy to understand and remember. In my next post, I'll go into the variable typing system, and describe the naming system.
SCALE defines a syntax format and provides a parser for that syntax. That's basically all that SCALE is. As I mentioned in my previous post, SCALE was inspired by and is based upon the .ini configuration files of Command and Conquer: Generals. A key feature of C&C:G's .ini system was its devilish simplicity. The syntax was simple and easy to understand - they were, after all, just configuration files (hence the .ini extension).
So here's what the syntax of SCALE looks like:
Material SpriteMaterial
{
~Shader
{
Filename = "Sprite.fx";
TechniqueName = "Sprite2D";
}
~ShaderPass
{
PassName = "Pass0";
RenderTarget = &BackBuffer;
}
~ShaderConstants
{
WorldMatrix = "WorldMatrix";
OrthoProjectionMatrix = "OrthoProjectionMatrix";
}
~Texture
{
Filename = "laying_rock7_largeDXT5.dds";
ShaderBinding = "Texture";
}
}
As you can see, the syntax is really simple. It's broken up into a simple hierarchy:
-Translation Units
-Objects
-Modules
-Variables
At the top, you have translation units. They're analogous to C/C++ translation or compilation units, in that they are effectively separate "modules". Each translation unit can be parsed without needing to look at any other translation units.
Each translation unit is typically represented by a file, but no limitation is imposed by the parser. Inside each translation unit is any arbitrary number of objects. Each object can be of any arbitrary type. Each object can also hold an arbitrary number of modules. And each module can hold an arbitrary number of arbitrarily typed variables with arbitrary values.
Confused? Let's take another look at the syntax we saw above. That code is actually an entire object - named "SpriteMaterial". The type of this object is a "Material". This works the same way as declaring variables C/C++: declare a type, then the variable name. In the body of the object, you are allowed any number of modules. A module is signified by the tilde prefix ('~'). For example, there are 4 modules in the above object: "Shader", "ShaderPass", "ShaderConstants", and "Texture". SCALE allows any number of modules, and they can have any name. SCALE also allows duplicate named modules - for example, it is legal to declare two modules named "Texture". Inside each module is a set of variables. SCALE also allows any number of variables, and they can be named however the application wishes.
Two types of comments are supported in SCALE: C-style comments and C++ style comments. Comments are merely skipped by the parser. They act just like they do in C++:
Foo Wilma
{
~Bar
{
Baz = 12.0;
//Baz = 3.14;
}
/*~Fred
{
}*/
}
Like in many languages, whitespace is mostly irrelevant in SCALE and has no syntactic meaning. Tokens in SCALE are delimited by a few things:
- Comments
- Braces
- Newlines
- Whitespace
- Semicolon
- Equals sign
That means that you can separate two identifiers with any of the above constructs. For example: this is entirely legal:
Mesh/*comment*/MyMesh{
~File
{
Name="fromage";
LazyLoad = /* hi, ma */ false;}
~Options{WeldVertices=true;Epsilon=0.01;}~Foo{Something=42;}
}
It's just unreadable, that's all.
So that's the syntax of SCALE. Very easy to understand and remember. In my next post, I'll go into the variable typing system, and describe the naming system.
SCALE III
"SCALE"?
SCALE is a wonderful little backronym that a friend and I came up with back in 2006. It stands for "Scalable Contant Abstraction Layer Engine". It's an overly fancy name for a helper library designed for usage in data-driven games.
History
Before I began dabbling in hobbyist game development, I liked to make mods for games. Back in 2003, I joined the Halogen team, which aspired to create a Halo total conversion mod for Command and Conquer: Generals. Following the disappearance of their existing coder at the time, I quickly assumed the role of lead coder for the project - and remained sole coder until the project ended in late 2006.
SCALE is a wonderful little backronym that a friend and I came up with back in 2006. It stands for "Scalable Contant Abstraction Layer Engine". It's an overly fancy name for a helper library designed for usage in data-driven games.
History
Before I began dabbling in hobbyist game development, I liked to make mods for games. Back in 2003, I joined the Halogen team, which aspired to create a Halo total conversion mod for Command and Conquer: Generals. Following the disappearance of their existing coder at the time, I quickly assumed the role of lead coder for the project - and remained sole coder until the project ended in late 2006.

Halogen was actually reasonably close to completion. By the middle of 2006, most of the UNSC faction was complete, and the Covenant units and structures were well on their way. We had plans for an open beta in mid-late 2006. By that time, Halogen had gained a reasonably large amount of popularity. We were well known in the C&C modding community, and we also made a small name for ourselves in the Halo community. Our updates were often mentioned on the front page of halo.bungie.org.
In September 2006, we effectively recieved a cease and desist letter. It wasn't actually sent by Microsoft, though. SketchFactor, a community manager at Bungie, elected to inform us of the bad news before Microsoft's lawyers got involved. And so, after 3 years of working on Halogen, we officially shut down the Halogen project. If you google "halogen mod" you may still be able to find some online articles if you want more information.

Of course, it was no secret why were were shut down. A few weeks after the notice, at X06, Microsoft's new Halo RTS "Halo Wars" was announced. Since Command and Conquer: Generals was an EA game, Halo was Microsoft's intellectual property, and Halogen was going to be direct competition, it's obvious why we were shut down.
But I never forgot the experience I gained through Halogen. Command and Conquer: Generals was an extremely moddable game - practically all game assets were exposed through a simple, easy to use plain text system. All in-game entity definitions were changeable through regular .ini files - making modding a breeze. This extreme moddability is what kept Command and Conquer: Generals alive for so long. Through my experience on Halogen, I learned the value of highly data-driven game design.
That's what SCALE is. It's not just a format, it's an engine for data-driven assets, based loosely on the .ini modding system used in Command and Conquer: Generals. Effectively, C&C:Generals was my inspiration for designing this system, and the great time I had modding it provides the motivation for SCALE's implementation.
Now that my overly lengthy history lesson is over, I'll begin talking about SCALE itself in more detail in a later post sometime.
Saturday, March 22, 2008
Macros
Once again I am boggled by the sheer evilness of macros. They're so innocent, like a cute little bunny. But the moment you turn your back you immediately find it gnawing on the back of your skull in an attempt to forcefully extract all of the remaining slivers of sanity which you hold so dear.
After implementing exceptions in SolSector Engine, I turned to improving some other error-related code: asserts. asserts are handy little macros which basically make an assertion that a certain condition must be true. Otherwise the program breaks. And it breaks loudly.
In C/C++, you use it like this:
assert(x != 0);
This means that the variable x should never be equal to 0, and if it is the program will break and an "Assertion Failed" dialog box will pop up (on MSVC, that is). Asserts were intended to be debugging tools, so they are only active in debugging mode. That is, they're only active if NDEBUG is not defined. Otherwise, they're removed by the preprocessor.
I see a little problem with this. All too often, I find that a particular problem happens when compiling in release mode, but for some reason doesn't happen in debug mode. In debug mode, code is compiled with no optimisations, and with full debugging information on. And it's often that it feels like I've got some freaky quantum errors going on... the errors magically disappear when I try to observe and debug them.
In debug mode, things like RTTI, exceptions, strict floating point precision, and optimisations are all turned off. That's a lot of different variables between release and debug mode to test - it means that if an error occurs in release but not debug mode, then any of the differences between the two modes are causing the problem. For example, the lack of RTTI may be making a dynamic_cast fail somewhere in release mode but not in debug mode. The lack of floating point exceptions might be screwing with math calculations somewhere. And the list goes on.
Turning asserts (aka. a vital debugging tool) off in release mode only exacerbates the problem. An assert might catch something that would be causing the error in release mode - but because the default library assert is tied to debug mode, I needed to write my own so that I could toggle it on/off at will without having to rely on NDEBUG. Having a custom assert also means that I don't have to deal with that ugly default MSVC-generated "assertion failed" dialog box.
Searching for resources, I came across this article. Read it. Now. If you didn't think macros were evil before, you should after reading that. It's not to say that macros shouldn't be used (indeed, assert is a perfectly valid use for a macro), but it highlights just how difficult macros can be. The average programmer should be wary of writing macros because, more often than not, you'll get them wrong.
I'm not even going to attempt writing my own assert macro now, and instead will use the one in the aforementioned article (it was released under the MIT license). And I can see that some of my existing macros need to be fixed. The mind-boggling evilness of macros strikes again.
After implementing exceptions in SolSector Engine, I turned to improving some other error-related code: asserts. asserts are handy little macros which basically make an assertion that a certain condition must be true. Otherwise the program breaks. And it breaks loudly.
In C/C++, you use it like this:
assert(x != 0);
This means that the variable x should never be equal to 0, and if it is the program will break and an "Assertion Failed" dialog box will pop up (on MSVC, that is). Asserts were intended to be debugging tools, so they are only active in debugging mode. That is, they're only active if NDEBUG is not defined. Otherwise, they're removed by the preprocessor.
I see a little problem with this. All too often, I find that a particular problem happens when compiling in release mode, but for some reason doesn't happen in debug mode. In debug mode, code is compiled with no optimisations, and with full debugging information on. And it's often that it feels like I've got some freaky quantum errors going on... the errors magically disappear when I try to observe and debug them.
In debug mode, things like RTTI, exceptions, strict floating point precision, and optimisations are all turned off. That's a lot of different variables between release and debug mode to test - it means that if an error occurs in release but not debug mode, then any of the differences between the two modes are causing the problem. For example, the lack of RTTI may be making a dynamic_cast fail somewhere in release mode but not in debug mode. The lack of floating point exceptions might be screwing with math calculations somewhere. And the list goes on.
Turning asserts (aka. a vital debugging tool) off in release mode only exacerbates the problem. An assert might catch something that would be causing the error in release mode - but because the default library assert is tied to debug mode, I needed to write my own so that I could toggle it on/off at will without having to rely on NDEBUG. Having a custom assert also means that I don't have to deal with that ugly default MSVC-generated "assertion failed" dialog box.
Searching for resources, I came across this article. Read it. Now. If you didn't think macros were evil before, you should after reading that. It's not to say that macros shouldn't be used (indeed, assert is a perfectly valid use for a macro), but it highlights just how difficult macros can be. The average programmer should be wary of writing macros because, more often than not, you'll get them wrong.
I'm not even going to attempt writing my own assert macro now, and instead will use the one in the aforementioned article (it was released under the MIT license). And I can see that some of my existing macros need to be fixed. The mind-boggling evilness of macros strikes again.
Thursday, March 20, 2008
Exceptions vs. Error Codes
When I first started SolSector engine, I was faced with a bit of a dilemma. I had to choose how to perform error reporting and recovery. I had two choices: error codes or C++ exceptions.
Error codes, like the HRESULT returns that DirectX uses, have bern tried and tested. They work well, and they're fast. However, they're a pain to manage. For every function that can possibly return an error, you need to check the return code. With hundreds of functions, this can be a major pain. Often, an error occurs deep in a function stack, and that error would need to be propagated through all the functions until it gets to higher function that can actually do something about the error. However, error codes are fast and really simple to use.
Exceptions, on the other hand, seem to be hated by a lot of people. I'd heard of the horrid execution speed of exceptions, and the apparent difficulty of writing exception-safe code. For instance:
void foo(char*, char*);
void bar()
{
foo(new char[5], new char[5]);
}
What's wrong with this code? Well, either one of those new's can throw an exception. Depending on how the compiler is feeling today, this could cause a memory leak because if an exception is thrown, foo() will never execute and the pointer to the allocated memory will be lost forever. I'm sure you can think of many more similarly nasty cases.
Initially, I chose to use error codes because of all the negative criticism regarding exceptions. And error codes worked well. I wrote a bunch of helpful macros to facilitate automatic error code returns and logging. But, as the project grew, error codes became more and more of a problem. Because error codes are only integers, they cannot store additional semantic information. For example, if a mesh loading function failed to load a file, I'd like to be able to know what the filename was. To alleviate this, I wrote a logging system so that whenever an error was returned from a function, it would automatically log the error (along with any additional helpful error/debugging information) in a global logger class. The returned error code would then be an index to the logged error message.
As you can imagine, this was very ugly. It seemed hackish and didn't feel like a clean solution (trying to hide all this ugly logging business behind macros, etc). It was at this point that I began to seriously consider exceptions.
I asked myself, why did I choose to avoid exceptions in the first place? I had a few main reasons:
Performance. I feared that exceptions would prove to be unacceptably slow.
Maintainability. I had heard that exceptions were notoriously difficult to work with and that it was hard to write exception-safe code.
Experience. Back when I began SolSector Engine (2006-ish) I hadn't had a large amount of experience working with exceptions yet. But I was already quite comfortable with error codes. Not having much experience with exceptions exacerbated my fears that I would not be able to write proper exception safe code.
I reviewed these reasons, and did a lot of research on the topic. As it turns out, my performance fears were unfounded. There were two things I was initially concerned about: the intrinsic cost of having exceptions on, and the cost of actually throwing an exception.
The intrinsic cost of exceptions is no lower than regular error codes. The general gist of it is that in any decent compiler, compiling with exceptions on just means that a function pointer (representing the exception handler) is popped on/off the stack when a function is entered/exited. Of course, there's probably more involved in the process, but calling a function with exceptions on is no more expensive than calling it and returning an error code. Another critical point is this: the standard library uses exceptions. If I want to catch out-of-memory errors and the like, I'd need exceptions to be on, anyway.
Of course, actually throwing an exception is quite slow. But let's stop and think for a moment. When are exceptions thrown? Exceptions are only thrown when an error happens. And when an error occurs, performance is the least of my worries. A great saying is, "throw exceptions in exceptional circumstances". If you're using exceptions for regular flow control, then you've got bigger problems than mere performance issues. This is also a great example of premature optimisation (which, as we all know, is the root of all evil). When an error occurs, it is far more important to have a useful error reporting system, rather than jumping through hoops and sacrificing code usability/maintainability (like I did with the logging system for error codes) to achieve better performance.
Maintainability of exceptions isn't that bad. Sure, writing exception-safe code is hard (very hard). But, it's not as bad as I would have imagined. Ever since I started using C++, I realised the value of RAII. For those of you who don't know, RAII stands for "Resource Acquisition Is Initialisation" and is pretty self-explanatory. Its meaning extends to deallocation - when an object is destroyed, it should clean up its own mess. In C++, this is made possible by the use of destructors: when an object is delete'd or goes out of scope, its destructor is called. My extensive use of RAII means that exception-safe code is an order of magnitude easier - when I throw an exception, I know that all my objects that I allocated on the stack will be cleaned up. And since I almost never deal with raw pointers (learn to love smart pointers!), I don't even have to worry about the memory I allocated in a function. With the usage of good, idiomatic C++, the maintenance costs if exceptions are lowered.
Recently, I've been using the .NET framework a lot more. In particular, I was exposed to C# while I was participating in the Google Highly Open Participation Contest, where I worked on improving the performance of the Mono C# Compiler. The compiler itself was written in C#, and I was able to increase the performance of the compiler by 5-10%. That's where I picked up C# - I learned it on the spot as I read through real code, learning as I went along. Exposure to such a "modern" language showed me the value of exceptions - error handling in .NET was far, far easier and more elegant than in SolSector Engine, for example. I could just set up a try/catch block around something, and if anything went wrong I could deal with it appropriately. In .NET, no more did I have to deal with massive blocks of if statements and error code checks.
So I finally made the jump to exceptions for SolSector Engine. Thanks to some handy macros and the power of regex, it only took me a few days to do (although testing will take much, much longer). It's still very early, but they seem to be working well so far and I haven't encountered any major problems. The error system is now a lot more robust and easy to use, I think. I got rid of the logging contraptions I used for error codes, and stored information inside exceptions themselves - much more convenient. The new code integrates better into the STL, too. Rather than setting up massive try/catch blocks and attempting to convert standard exceptions into error codes, I can now just not bother and allow the exceptions to pass through. It's the same with constructors - exceptions are the best way to signal a failed constructor.
I wrote my exceptions to be similar to those found in .NET - as they were simple and familiar. It's still early, and lots of testing needs to be done, but for now it seems that I made the right choice. From now on, it'll be exceptions all the way.
Monday, March 17, 2008
Implementing HDR in Clouds
It seems as if High Dynamic Range lighting (HDR) is becoming all the rage for gaming graphics, nowadays. I’ve seen it used in a multitude of games thus far. I remember my first HDR experience. It was back in 2004, when FarCry had just released its 1.3 patch enabling HDR on Geforce 6 series cards. Since I was between upgrades, I was using a Radeon X300 at the time. So I went to a friend’s house to try it out on his 6600GT. And I was stunned at the oversaturated, glaring bloom effects.
I’d wanted to implement my own over-the-top HDR ever since.
What is HDR?
So for the uninitiated, what is HDR? In the real world, we humans experience a vast range of contrast. We can see very bright objects, such as the sun, as well as very dark objects such as a moonlit scene. In computers and modern graphics, however, we're limited to a very, very small range. The brightest colour that can be expressed in a 32-bit ARGB texture is (255, 255, 255, 255), or pure white. And it isn't very bright. So we use a technique called HDR to alleviate this. When rendering the scene, we render it to a format with a very high dynamic range, for example a 64-bit texture. Most commonly, we use a floating point format in the form: A16R16G16B16F, which means a 16-bit float for each component. Each component can now roughly store a value up to about ~65,000... much better than the 255 we were limited to on 32-bit ARGB.
That means that in our scene, very very bright objects will have colours greater than 255, while dark objects will be able to have precise values near 0 (thanks to floating-point). But now we've got a problem. Regular monitors and displays can't display such bright values: the hardware itself is still limited to 8-bit component RGB, with its annoying 255 maximum. So an operation called tonemapping is performed. Tonemapping is the process of converting the HDR image into a Low Dynamic Range image (LDR), so that the monitor can actually display it. This means shifting and squeezing the brightness of a scene so that it best fits within the display limits of the monitor. This is why, in HDR-rendered scenes, the brightness changes as you look at bright/dark objects.
After tonemapping, you've got an LDR image which you can now display to the monitor. That's really all that HDR needs. But if you've ever used a camera, you may notice some things are missing from our HDR scene. In a camera (and in the human eye), we see that bright things tend to get lens flares, as well as blooming. So often you'll see these things implemented along with HDR (and, indeed, seem to have become synonymous with the term). Bloom, starring and lens flares are all post-processing effects, and they simulate the effect of light passing through a lens and can greatly increase the image quality of a scene. More information can be found in the resources I'll list later on.
HDR in Clouds
Clouds doesn’t use any dynamic lighting. All shading done on the clouds is static – cheap shader approximations because I didn’t want to implement anything overly complicated. Nevertheless, I made the decision to implement HDR because it provided an excellent real-world test of SolSector Engine’s shader system.
I set out by reading up on the relevant material. As HDR had gained popularity for use in games over the past few years, there was no shortage of information. The first thing I took a look at was the famous implementation by Masaki Kawase, in the form of his demo dubbed “Rthdribl” (Real-Time High Dynamic Range Image Based Lighting). It’s available here. I used his demo as a base for what HDR should look like - and set out to write my own shaders in HLSL from scratch.
The full HDR pipeline is pretty complex. I drew up an initial diagram for the pipeline: (warning: large)
I’d wanted to implement my own over-the-top HDR ever since.
What is HDR?
So for the uninitiated, what is HDR? In the real world, we humans experience a vast range of contrast. We can see very bright objects, such as the sun, as well as very dark objects such as a moonlit scene. In computers and modern graphics, however, we're limited to a very, very small range. The brightest colour that can be expressed in a 32-bit ARGB texture is (255, 255, 255, 255), or pure white. And it isn't very bright. So we use a technique called HDR to alleviate this. When rendering the scene, we render it to a format with a very high dynamic range, for example a 64-bit texture. Most commonly, we use a floating point format in the form: A16R16G16B16F, which means a 16-bit float for each component. Each component can now roughly store a value up to about ~65,000... much better than the 255 we were limited to on 32-bit ARGB.
That means that in our scene, very very bright objects will have colours greater than 255, while dark objects will be able to have precise values near 0 (thanks to floating-point). But now we've got a problem. Regular monitors and displays can't display such bright values: the hardware itself is still limited to 8-bit component RGB, with its annoying 255 maximum. So an operation called tonemapping is performed. Tonemapping is the process of converting the HDR image into a Low Dynamic Range image (LDR), so that the monitor can actually display it. This means shifting and squeezing the brightness of a scene so that it best fits within the display limits of the monitor. This is why, in HDR-rendered scenes, the brightness changes as you look at bright/dark objects.
After tonemapping, you've got an LDR image which you can now display to the monitor. That's really all that HDR needs. But if you've ever used a camera, you may notice some things are missing from our HDR scene. In a camera (and in the human eye), we see that bright things tend to get lens flares, as well as blooming. So often you'll see these things implemented along with HDR (and, indeed, seem to have become synonymous with the term). Bloom, starring and lens flares are all post-processing effects, and they simulate the effect of light passing through a lens and can greatly increase the image quality of a scene. More information can be found in the resources I'll list later on.
HDR in Clouds
Clouds doesn’t use any dynamic lighting. All shading done on the clouds is static – cheap shader approximations because I didn’t want to implement anything overly complicated. Nevertheless, I made the decision to implement HDR because it provided an excellent real-world test of SolSector Engine’s shader system.
I set out by reading up on the relevant material. As HDR had gained popularity for use in games over the past few years, there was no shortage of information. The first thing I took a look at was the famous implementation by Masaki Kawase, in the form of his demo dubbed “Rthdribl” (Real-Time High Dynamic Range Image Based Lighting). It’s available here. I used his demo as a base for what HDR should look like - and set out to write my own shaders in HLSL from scratch.
The full HDR pipeline is pretty complex. I drew up an initial diagram for the pipeline: (warning: large)
 But, this was unoptimised and took up a horrific amount of memory:
But, this was unoptimised and took up a horrific amount of memory: After some reorganisation, I was able to significantly reduce the amount of buffers to just a few, but it really convoluted the pipeline: (warning, very large)
After some reorganisation, I was able to significantly reduce the amount of buffers to just a few, but it really convoluted the pipeline: (warning, very large)

Problems
One of the main problems was simply getting it to look right. Initially, I used the Reinhard operator to tonemap the HDR scene, but I found that it was ill-suited for this purpose. It would overdarken bright scenes, and overbrighten dark scenes. In other words, the dynamic range was a little too high. After many, many hours of tweaking, I resorted to simply removing the Reinhard operator in favour of a simple linear one. The Reinhard operator (as well as the Reinhard improved operator) would simply reduce contrast over the entire scene to fit the HDR space into LDR - a byproduct of its hyperbolic curve, even if it did guarantee that the HDR scene mapped fully into LDR. It may have been theoretically ideal, but it just didn't look good. The linear operator, in addition to a simple luminance clamp, is certainly not "technically" correct. But it doesn't matter; it looks nice and the tonemapping effect is now quite subtle (as it should be).
HDR is just one of those things that needs a lot of tweaking to get right. Especially the tonemapping, and various parameters for bloom/glare/etc.
For anyone looking to implement HDR for themselves, here are a few of the things that helped me along the way:
- Masaki Kawase's GDC 2004 slides, available here and here. Go through them both!
- For those interested in some theory, be sure to check out Erik Reinhard's whitepaper here.
- The DirectX SDK samples. They provide full source code and explanations, and a heck of a lot of good information. See: HDR Lighting (Direct3D 9), HDRLighting Sample (with executable and source code available the SDK), HDRDemo Sample. The HDRLighting Sample is particularly useful. It implements the entire HDR pipeline and the HLSL shader code provided was a great reference point.
Sunday, March 16, 2008
Multithreading in Clouds
The Clouds demo posed an interesting problem for me. It required large amounts of CPU power, while at the same time I was finding it difficult to optimise the code any further. The cloud generation and render setup was hitting the CPU hard - and only 50% of my dual core CPU was being utilised.
While I had dabbled in multithreading before, I'd never applied it to any real-life applications. Clouds was in a unique situation: it was a CPU-intensive application, but had absolutely no requirements regarding latency. So I was free to design the most rediculously input-latency-heavy system I could think of.
I immediately split the application into 2 threads - simulation and render. Simulation would generate perlin noise, do the day/night cycles, and everything relating to the world itself. The render thread would, well, render. The render thread and the simulation thread are completely decoupled - they can both run at any speed and neither would affect the other.
I chose a buffered approach to communicate between the two threads. The simulation thread would write information to a buffer, and the render thread would then take that information and use it to draw stuff to the screen. I started off with 3 buffers - one for simulation and two for render. Since the simulation thread was locked to 10hz and the render thread ran as fast as it could, the render thread needed to "fill in the blanks" somehow between each 100ms long timestep. So the render thread uses its two buffers to interpolate between, to produce smooth looking results while the simulation thread writes to the third buffer. Here's what it looks like:

Here's the problem: this leaves the system open to data starvation. If the simulation thread finishes its simulation before the render thread is done, then the simulation thread has to sit there and wait until the render thread is done with one of its two buffers. However, if the render thread finishes before the simulation thread is done, then the render thread has to sit there and wait for the simulation thread to finish with its current timestep before it can continue interpolating.
So I added a fourth buffer. The addition of the fourth buffer meant that input latency had grown to a rediculously massive 400-500ms. But that didn't matter, since I didn't have any input that could affect the simulation! The fourth buffer sits in between the simulation thread and render thread, and it donates itself to whoever needs it most. If the simulation thread is done before the render thread, the fourth buffer goes to the simulation thread so it can begin writing the next timestep's data. If the render thread is done before the simulation thread, the fourth buffer goes to the render thread so it can continue interpolating and rendering stuff. So here's the final flow:

Because of this buffered approach and the fact that the two threads were completely decoupled, syncronisation overhead is basically nonexistant. However, this system would not be suitable for usage in a real game, since it introduces impossibly large amounts of input latency to the game.
However, thanks to the helpful members of GameDev.Net, I now have some ideas for how to implementation of this system in a real game.
While I had dabbled in multithreading before, I'd never applied it to any real-life applications. Clouds was in a unique situation: it was a CPU-intensive application, but had absolutely no requirements regarding latency. So I was free to design the most rediculously input-latency-heavy system I could think of.
I immediately split the application into 2 threads - simulation and render. Simulation would generate perlin noise, do the day/night cycles, and everything relating to the world itself. The render thread would, well, render. The render thread and the simulation thread are completely decoupled - they can both run at any speed and neither would affect the other.
I chose a buffered approach to communicate between the two threads. The simulation thread would write information to a buffer, and the render thread would then take that information and use it to draw stuff to the screen. I started off with 3 buffers - one for simulation and two for render. Since the simulation thread was locked to 10hz and the render thread ran as fast as it could, the render thread needed to "fill in the blanks" somehow between each 100ms long timestep. So the render thread uses its two buffers to interpolate between, to produce smooth looking results while the simulation thread writes to the third buffer. Here's what it looks like:

Here's the problem: this leaves the system open to data starvation. If the simulation thread finishes its simulation before the render thread is done, then the simulation thread has to sit there and wait until the render thread is done with one of its two buffers. However, if the render thread finishes before the simulation thread is done, then the render thread has to sit there and wait for the simulation thread to finish with its current timestep before it can continue interpolating.
So I added a fourth buffer. The addition of the fourth buffer meant that input latency had grown to a rediculously massive 400-500ms. But that didn't matter, since I didn't have any input that could affect the simulation! The fourth buffer sits in between the simulation thread and render thread, and it donates itself to whoever needs it most. If the simulation thread is done before the render thread, the fourth buffer goes to the simulation thread so it can begin writing the next timestep's data. If the render thread is done before the simulation thread, the fourth buffer goes to the render thread so it can continue interpolating and rendering stuff. So here's the final flow:

Because of this buffered approach and the fact that the two threads were completely decoupled, syncronisation overhead is basically nonexistant. However, this system would not be suitable for usage in a real game, since it introduces impossibly large amounts of input latency to the game.
However, thanks to the helpful members of GameDev.Net, I now have some ideas for how to implementation of this system in a real game.
Saturday, March 15, 2008
Clouds Demo
Well, the Clouds demo is pretty much done. The Clouds demo was written to test specific systems in the SolSector Engine. Specifically, the resource management systems, the mesh/material/texture interaction systems and the usage of advanced shaders.
Here's a youtube video:
The music is "Primavera" by Ludovico Einaudi. The sprites for the clouds were borrowed from this article at Gamasutra.
The demo features:
- DirectX10 3D renderer
- Dynamic, perlin-noise generated volumetric clouds
- High Dynamic Range lighting
- Dynamic day/night cycle
- Multithreaded, multi-core optimised design
It runs at a blazing 20fps on my Core 2 Duo E6600 and Geforce 8800GTS machine. It's completely CPU bound, because of the massive number of sprites I'm dealing with.
Cloud Generation
The clouds are generated through simple perlin noise, via libnoise. Since realism wasn't exactly a key goal here, I just needed a quick and dirty way to generate nice patterns. Remembering the Render>Clouds filter in Photoshop, I turned to perlin noise. Perlin noise is a type of coherent noise defined by Ken Perlin. It's seen a lot of use all over the place, especially in dynamically-generated content such as these clouds.
Originally, I had planned to use a more complex simulation to generate more realistic clouds. Initially, I took a look at the works presented by Dobashi et al. in their whitepaper. They utilised a simplified fluid dynamics simulation model, and during preproduction of the demo I attempted a quick implementation of their simulation. Needless to say, I failed. I didn't have the necessary physics background to understand what they were doing, and the simulation ran too slowly to be of any use anyway. It was at this point that I turned to simpler approaches. I found a very informative article on Gamasutra regarding the cloud rendering system used in Microsoft Flight Simulator 2004, authored by Niniane Wang of Microsoft. There was also a plethora of information available on GameDev.Net, but it most of it wasn't all too relevant.
I chose perlin noise because it was simple. However, it was also quite slow. The clouds are essentially just a 128x128 grid of perlin noise - which means a grand total of 16,384 perlin noise samples to regenerate per tick. And it needed to be done on the CPU. I was able to leverage this by implementing a multi-threaded system, which I'll talk about later. All you need to know right now is that, essentially, the generation of the perlin noise came "for free" if you have a dual-core processor or better.
The perlin noise generated was on a 2D plane, however. To achieve real, proper volume, I'd need to generate unique perlin noise in all 3 dimentions. This would have greatly increased the number of perlin noise samples required per frame (roughly by an order of magnitude). So I faked it - wrote a quick and dirty software bright-pass filter and applied it to the generated 2D perlin noise. This eliminated the darker regions of the noise, and when stacked above each other gave a roughly pyramidal shape for each cloud. To scroll and billow the clouds, it was as simple as adding an offset to the inputs to the perlin noise generator.
To render the clouds themselves, a simple 128x128x10 sprite grid was placed, and each sprite was made to be more/less transparent, depending on the value of the perlin noise corresponding to each sprite.
I'll post more details about the workings of the Clouds demo later on. I'll also post a higher-res version of the demo video, as well as the actual executable if I can find somewhere to host it.
Here's a youtube video:
The music is "Primavera" by Ludovico Einaudi. The sprites for the clouds were borrowed from this article at Gamasutra.
The demo features:
- DirectX10 3D renderer
- Dynamic, perlin-noise generated volumetric clouds
- High Dynamic Range lighting
- Dynamic day/night cycle
- Multithreaded, multi-core optimised design
It runs at a blazing 20fps on my Core 2 Duo E6600 and Geforce 8800GTS machine. It's completely CPU bound, because of the massive number of sprites I'm dealing with.
Cloud Generation
The clouds are generated through simple perlin noise, via libnoise. Since realism wasn't exactly a key goal here, I just needed a quick and dirty way to generate nice patterns. Remembering the Render>Clouds filter in Photoshop, I turned to perlin noise. Perlin noise is a type of coherent noise defined by Ken Perlin. It's seen a lot of use all over the place, especially in dynamically-generated content such as these clouds.
Originally, I had planned to use a more complex simulation to generate more realistic clouds. Initially, I took a look at the works presented by Dobashi et al. in their whitepaper. They utilised a simplified fluid dynamics simulation model, and during preproduction of the demo I attempted a quick implementation of their simulation. Needless to say, I failed. I didn't have the necessary physics background to understand what they were doing, and the simulation ran too slowly to be of any use anyway. It was at this point that I turned to simpler approaches. I found a very informative article on Gamasutra regarding the cloud rendering system used in Microsoft Flight Simulator 2004, authored by Niniane Wang of Microsoft. There was also a plethora of information available on GameDev.Net, but it most of it wasn't all too relevant.
I chose perlin noise because it was simple. However, it was also quite slow. The clouds are essentially just a 128x128 grid of perlin noise - which means a grand total of 16,384 perlin noise samples to regenerate per tick. And it needed to be done on the CPU. I was able to leverage this by implementing a multi-threaded system, which I'll talk about later. All you need to know right now is that, essentially, the generation of the perlin noise came "for free" if you have a dual-core processor or better.
The perlin noise generated was on a 2D plane, however. To achieve real, proper volume, I'd need to generate unique perlin noise in all 3 dimentions. This would have greatly increased the number of perlin noise samples required per frame (roughly by an order of magnitude). So I faked it - wrote a quick and dirty software bright-pass filter and applied it to the generated 2D perlin noise. This eliminated the darker regions of the noise, and when stacked above each other gave a roughly pyramidal shape for each cloud. To scroll and billow the clouds, it was as simple as adding an offset to the inputs to the perlin noise generator.
To render the clouds themselves, a simple 128x128x10 sprite grid was placed, and each sprite was made to be more/less transparent, depending on the value of the perlin noise corresponding to each sprite.
I'll post more details about the workings of the Clouds demo later on. I'll also post a higher-res version of the demo video, as well as the actual executable if I can find somewhere to host it.
Sunday, March 9, 2008
Hello World
So this is the blogosphere. Not as glamorous as I had imagined.
A little about me: I'm a hobbyist game developer, and I like to write games in my spare time. I'm fairly well-versed in C++, and I know a little C# on the side. I'm currently working on an ambitious project named "SolSector Engine". I plan for it to be a full-scale, DX10 3D game engine written in C++.
What's with the name? Well, "SolSector" is actually the name for a future game that I and a friend plan to start someday. And the game needed an engine. So SolSector Engine was born. I usually shorten SolSector Engine to SSE, not to be confused with Intel's Streaming SIMD Extensions. If I mention SSE, I really do mean SolSector Engine and not an instruction set for instruction-level parallelism in CPUs.
So what is SolSector Engine capable of currently? The engine is still in its early phases of development. However, it's capable of some pretty neat stuff. It features a complete DirectX10 renderer, and systems for the automatic management of resources, sound, input, and windowing. Because it uses Direct3D10, it is Vista-exclusive.
Right now, I'm writing a small tech demo to test out the various features and subsystems of SolSector Engine. It's called "Clouds", and should be ready in the coming weeks. It won't be particularly pretty or anything, since it is designed to stress-test the engine, not to produce nice graphics (although that's a bonus).
I'll be making more posts about the Clouds demo and SSE in general later on.
A little about me: I'm a hobbyist game developer, and I like to write games in my spare time. I'm fairly well-versed in C++, and I know a little C# on the side. I'm currently working on an ambitious project named "SolSector Engine". I plan for it to be a full-scale, DX10 3D game engine written in C++.
What's with the name? Well, "SolSector" is actually the name for a future game that I and a friend plan to start someday. And the game needed an engine. So SolSector Engine was born. I usually shorten SolSector Engine to SSE, not to be confused with Intel's Streaming SIMD Extensions. If I mention SSE, I really do mean SolSector Engine and not an instruction set for instruction-level parallelism in CPUs.
So what is SolSector Engine capable of currently? The engine is still in its early phases of development. However, it's capable of some pretty neat stuff. It features a complete DirectX10 renderer, and systems for the automatic management of resources, sound, input, and windowing. Because it uses Direct3D10, it is Vista-exclusive.
Right now, I'm writing a small tech demo to test out the various features and subsystems of SolSector Engine. It's called "Clouds", and should be ready in the coming weeks. It won't be particularly pretty or anything, since it is designed to stress-test the engine, not to produce nice graphics (although that's a bonus).
I'll be making more posts about the Clouds demo and SSE in general later on.
Subscribe to:
Posts (Atom)

